(Event/Seminar후기) NAVER Vision AI Hackathon 본선 대회에 참여했습니다!

지난 2019년 1월 2일부터 시작된 네이버 Vision AI 해커톤 대회에 두달간 참여하며 겪은 소중한 경험을 나눕니다. 비록 우승권에 들지 못한 채 대회를 마감했지만 그 자체로 많은 깨달음을 얻을 수 있었습니다. 쟁쟁한 팀의 팀원 분들을 오프라인에서 만날 수 있었던 본선 대회에 다녀온 후기입니다.
지난 1월 2일부터 시작된 네이버 Vision AI 해커톤 대회가 어제로 끝이 났습니다. 두달간 정말 쉼없이 달려오며 많은 우여곡절을 겪고 소중한 추억을 만들었습니다. 비록 우승권에 들지 못한 채 중하위권에서 대회를 마감했지만 그 자체만으로도 뿌듯하고 많은 깨달음을 얻었습니다. 이번 포스팅은 쟁쟁한 팀의 팀원 분들을 오프라인으로 만날 수 있었던 오프라인 본선 대회에 다녀온 후기입니다~

본선 오프라인 대회는 춘천 네이버 커넥트원에서 진행되었습니다. 당일 아침 분당 정자역에서 버스를 타고 네이버 본사(그린팩토리) 커넥트홀에 모인 후 다함께 관광버스를 타고 출발했습니다.


2층에서 명찰과 간식 샌드위치, 참가등록 확인을 받고 커넥트홀로 입장할 수 있었습니다.


시간을 딱 맞춰 도착해서 많은 분들이 도착해 계셨습니다. 사진으로 모든 분을 담지는 못했지만 본선 대회엔 40팀이 진출했고, 한 팀당 최대 인원이 세 명 까지이기 때문에 제가 앉은 자리 뒤로도 많은 분들이 계셨어요. 다들 본선 대회까지 오셔서 싱글벙글하셨지만 저희 팀은 예선 2차에서 꼴찌를 간신히 면하고 진출했기 때문에 커넥트홀에 입장할 때부터 주눅이 들어 있었습니다 ㅠㅠ






대회 일정과 간단한 주의사항을 듣고 바로 춘천으로 출발했습니다. 춘천까지는 한시간 40분정도 걸렸고, 가는 동안 Inference 함수를 수정해서 극적으로 mAP스코어를 0.20정도 올릴 수 있었습니다. 실무 경험이나 대회 경험이 많지 않아 대회 내내 무조건 네트워크 구조에만 집중해 왔었는데, 인퍼런스도 학습 못지 않게 중요하다는 사실을 뒤늦게나마 알았습니다.

커넥트원 시설은 외관을 제외한 건물 전체가 촬영금지 구역이라서 지정된 포토존에서만 사진을 찍을 수 있었습니다. 해시태그 이벤트도 같이 하고 있더라고요 ㅎㅎ 선물은 맨투맨과 노트, 손목보호대와 스티커를 받았습니다.
대회 기간 동안 운영진, 멘토, 다른 참가자 분과 실시간으로 커뮤니케이션을 할 수 있는 sli.do채널이 운영되었습니다. 정말 각종 공식 이벤트와 드립들의 향연들이 펼쳐졌는데요, 자칫 삭막하게 일만 할 수 있는 대회가 되지 않도록 신청곡도 받고 소소한 이야기를 나눌 수 있어서 너무 좋았습니다. 커넥트원에 운동시설이 있어서 같이 운동을 하자는 분, 혼자와서 식사 같이 할 사람을 찾는 분, 딥러닝을 공부하시는 분이라면 누구나 아는 말로만 듣던 Sung Kim 교수님, 라인의 에반젤리스트님까지 다양한 분들께서 소통을 하셨습니다. Sung Kim 교수님은 실제 오시기도 했다는데 정신이 없어서 저는 뵙지 못했습니다 ㅠㅠ
대회와 동시에 한켠에서는 네이버 취업상담과 클로바 AI 비전팀의 인공지능 멘토링, NSML 서비스 관련 멘토링도 진행되었습니다. 멘토님들의 열정이 정말 대단하셔서 당초 예정된 시간을 훌쩍 넘긴 늦은 밤까지 자리에 계셔 주셨어요. 평소 이런 전문적인 조언을 구할 곳이 없어 저희 팀에게는 너무 소중한 기회였습니다. 그동안 궁금했던 부분들을 마음껏 여쭤볼 수 있었거든요. 네이버 내 생활과 관련한 소소한 이야기들도 들려 주시고, 간간히 공부 팁도 알려 주셨습니다. 다만 경황이 없어 취업상담을 못 가본 것이 크디큰 아쉬움으로 남네요…
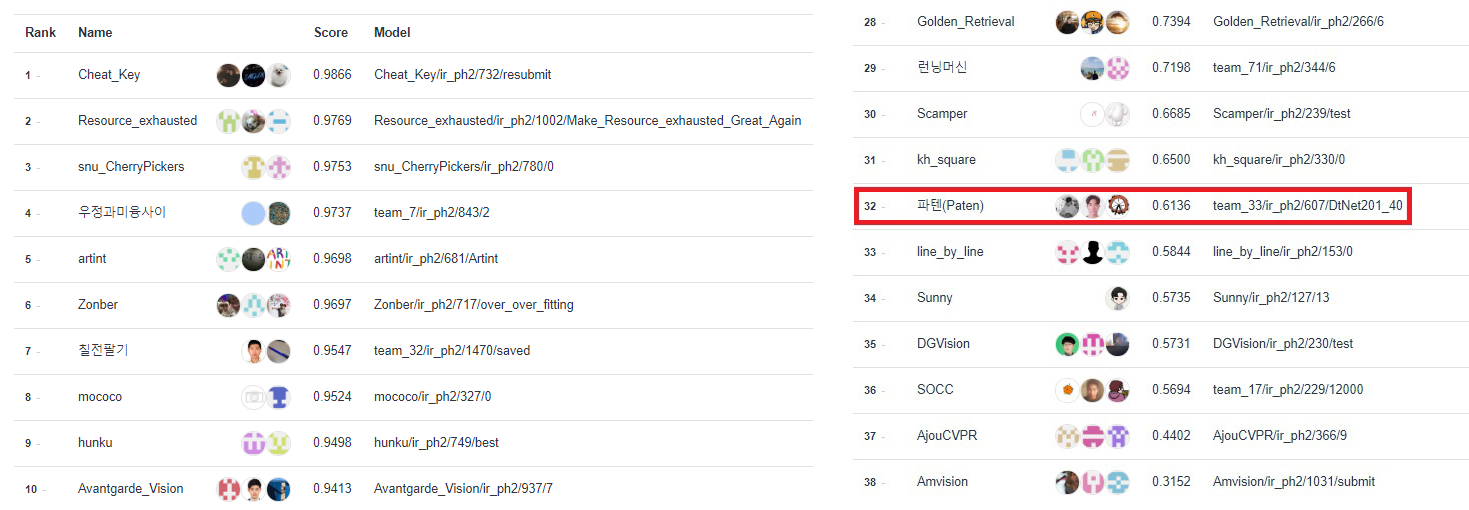
리더보드 상위권은 정말 박진감이 넘쳐서 보는 재미가 있었습니다. 심해에 있던 팀이 단숨에 상위권에 진입하기도 하고, 특히 우승을 거머쥔 3등 snu_CherryPickers팀은 대회 종료 불과 30분 전에 9등이나 제치고 랭킹되어 탄성을 자아냈습니다. 진행자님 소개처럼 저희 팀도 예선대회부터 왠지 대회 후반부에 닉값을 제대로 할 팀으로 흥미롭게 지켜본 팀인데 결국 우승을 하셨네요.
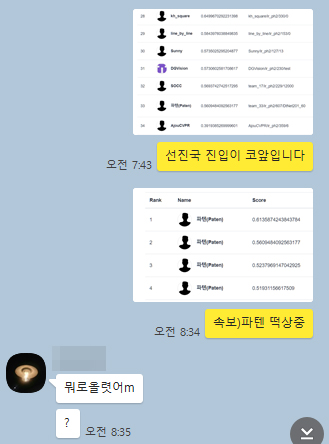
저희 팀은 사실상 꼴찌(mAP Score 0.3064)로 올라왔지만 포기하지 않고 모델 구조 개선과 Data Imbalance 해결, 파라미터 튜닝, Inference 함수 수정을 통해 두배 정도 성능을 개량하여 32등(0.6136)으로 마감했습니다. 앙상블 적용과 Query Expansion과 같은 부가적인 기법들을 적용했더라면 상위권 랭크도 노려볼만했는데 정말 마지막까지 아쉬움만 잔뜩 남네요. 저희는 오히려 Data Imbalance 문제에 집중하느라 시간을 꽤 소모했고, 여러 분류기를 테스트하는 기간이 길어 본질에 집중할 시간을 허비했던 것 같아요. 노하우도 그리 많지 않아 무조건 에폭만 높으면 되는 줄 알고 3000번 돌리기도 하고…프리트레인 모델을 사용하지 않았었습니다. 결국은 feature engineering에 대한 노하우와 SOTA 논문의 높은 이해도, 빠른 적용력과 팀원간 의사소통이 원활한 팀이 상위권에 랭크될 수 있었습니다.
특히 백본 모델(DenseNet201)의 퍼포먼스가 싱글 분류 성능은 좋지만 시간이 오래 걸려 한번 서밋할 때마다 20분씩 소요되는 바람에 그야말로 긴장의 연속이었어요. 그나마도 NSML이 대회를 위해 제공해준 TPU가 P40(24GB)여서 이정도 퍼포먼스가 나왔지, 더 낮은 하드웨어였다면 학습도 시작하지 못했을 거예요.
정말 많은 것을 반성하고 느끼게 해준 대회였습니다. 역시 학문과 연구는 겸손한 자세로 임하고 고정관념에 사로잡히지 않아야 할 것 같습니다. 이런 큰 대회에 처음으로 출사표를 내고 뜻밖에 본선까지 진출하게 되어 티는 내지 않았지만 속으로 자만심에 빠져 있었는데, 1, 2, 3등팀 모두 Image Retrieval 분야는 처음이라는 우승 소감을 듣고 깊이 반성하는 계기가 되었습니다. 대회 컷오프 때마다 아등바등 올라오긴 했지만 ‘왜 그때 그걸 하려다 말았을까’ 하는 아쉬움, 조금만 덜 잘걸…하는 후회가 남네요. 비록 저희 팀은 커넥트원 숙소를 구경하지 못했지만 그 전에 미리 어제 잘 잠을 늘려 두지 못한 제 잘못이죠 ㅠㅠ
대회에 참여한 지난 두어 달 동안 온갖 삽질과 고생을 하며 많은 것을 배웠습니다. 학교에서 배운 것보다 현장에서 배운 것이 더 값지고 소중하네요. 이론도 중요하지만 그걸 구현할 수 있어야 일류가 된다는걸 다시금 깨달았습니다. Naver Vision AI대회에서 얻은 교훈과 동기를 소중히 간직한 채 두 번째 대회를 준비해 봐야겠습니다.
이번 대회에서 느낀 점.
1. 파인튜닝과 앙상블은 Image Retrieval을 비롯한 비전 분야 컴퍼티션에서는 굉장히 자주 쓰입니다.(다만 DenseNet201같이 무거운 모델은 submission 시간을 초과할 수 있어 앙상블이 위험합니다.)
2. Data Imbalance 문제는 꽤 중요하지만, 학습 결과에 지장을 줄 정도가 아니라면 중요도 비중이 낮습니다.
3. Feature Engineering은 거의 모든 인공지능 학습에서 필수입니다.
4. 높은 에폭이 반드시 좋은 학습을 보장하지는 않습니다. GAN을 학습할땐 G와 D의 불균형이 생기기 전까지 오래 학습했는데, 이번 대회에서는 데이터셋 크기가 커서 그런지는 몰라도 40에폭이 제일 성능이 좋았습니다. (저희는 30~3000에폭까지 고루고루 테스트해보았습니다. 40->30->70->80 순으로 성능이 제일 좋고 그 이후부터는 오버피팅이 굉장히 심해졌습니다.)
5. Query Expansion은 매우 강력한 성능을 보장하지만 필수는 아닙니다.
6. DenseNet201은 사랑입니다. 많은 것을 볼수록(큰 RF와 큰 커널 사이즈일수록), 하드웨어가 받쳐줄수록 더 좋은 성능을 내 줍니다.
7. 프리트레인 모델을 사용했다면 프리트레인 학습에서 정규화 시 사용한 mean과 std로 우리의 데이터셋을 standardization해야 합니다. (테스트셋도 마찬가지입니다.)