(Event/Seminar후기) NVDIA AI Conference 2019에 다녀왔습니다.

지난 7월 1일과 2일 양일간 코엑스 그랜드볼룸 일대에서 열린 NVIDIA AI Conference 2019에 다녀왔습니다. 올해는 작년보다 더 많은 CUDA 최적화 세션들이 준비되어 현실적인 조언들을 많이 구할 수 있었습니다.


지난 7월 1일과 2일 양일간 코엑스 그랜드볼룸 일대에서 열린 NVIDIA AI Conference 2019에 다녀왔습니다. 올해는 작년보다 더 많은 CUDA 최적화 세션들이 준비되어 현실적인 조언들을 많이 구할 수 있었습니다. 더불어 그래픽 컴퓨팅 회사로 시작한 엔비디아가 전세계적으로 GPU Computing, AI 부문에 컴퓨팅 파워를 공급하는 하드웨어 제조뿐 아니라 관련 연구, 솔루션들을 제공하는 회사로 발돋움해가는 과정에서 미래를 엿볼 수 있었습니다. 경제 전문가들은 인공지능 기술이 글로벌 GDP 기준 16조 달러의 경제적 가치를 창출하고 2022년 5800만여 개의 일자리를 만들어낼 것으로 예상하고 있습니다. 또한 전 세계 4천여개의 인공지능 스타트업들이 smart city, public safety, transportation과 같은 분야에서 활발히 연구하는 등 전방위적인 민관 주도 대규모 투자가 이루어지고 있는 상황입니다.
★ 강연 요약 포스팅 (업데이트중) ★
1. [NVIDIA AI Conference] Tensorcore를 이용한 딥러닝 학습 가속을 쉽게 하는 방법
2. [NVIDIA] GPU를 활용한 Image Augmentation 가속화 방안 - DALI
3. [NVIDIA] GPU Profiling 기법을 통한 Deep Learning 성능 최적화 기법 소개
4. [NVIDIA] 효율적인 Deep Learning 서비스 구축을 위한 핵심 애플리케이션 - NVIDIA TensorRT Inference Server




컨퍼런스 세션들은 이튿날인 2일부터 진행되었습니다. 산학 전반을 아우르는 큰 행사이다보니 중학생 정도의 어린 친구들부터 시작해 의사결정에 참여하시는 나이가 지긋하신 분들까지 정말 다양한 각계각층의 전문가와 비즈니스맨들이 모인 행사였습니다. 또한 작년보다 CUDA 최적화 부문의 세션이 좀 더 추가되어 TensorCore를 이용해 딥러닝 학습을 가속하는 방법부터 GPU를 활용한 Image Augmentation 라이브러리인 DALI, Nsight system을 활용한 GPU Profiling 튜토리얼까지 본격적으로 졸업논문 연구를 시작한 저에게 도움이 될만한 토픽들이 참 많았습니다. 특히 비즈니스 세션이 꽤 있었다는 점에서 산업이 어느정도 성숙기에 접어들었고 다양한 기업들과 연구소에서 더이상 아카데미 수준에서만 머물지 않고 산업으로 인공지능 기술의 저변을 확대하는 것에 집중하고 있다는 것을 체감할 수 있었습니다. 불과 작년까지만 해도 실험적인 기술이라는 인식이 존재했으나 지금은 어느정도 침착함을 유지하며 대응하는 모습입니다.

올해 키노트에서는 Data Sceicne, CUDA Ecosystem에 대한 내용이 거의 핵심이었다고 보아도 무방할 정도로 자사 플랫폼과 장비, 시설 소개에 대부분의 시간을 할애하는 모습이었습니다. 데이터 사이언스 연구는 Hyperscale CPU server과 Supercomputing 사이에 위치한 마켓이기 때문에 해당 분야에 자사의 고속 컴퓨팅 기술을 지원하겠다고 언급하며 DGX-2, Data science server 두 종의 제품군을 소개했습니다. 이 제품군들이야 워낙 유명하니 그러려니 하고 들었지만 CUDA to ARM 슬라이드에서 꽤 충격을 받았습니다. ARM과 협업해 CUDA 가속을 ARM칩 위에서 지원하겠다는 내용으로 올 하반기에 릴리즈 예정이라고 하네요. CUDA 가속을 지원하는 ARM서버의 그림이 잘 그려지진 않지만 고속컴퓨팅 분야에서의 주도권을 놓치지 않겠다는 강력한 의도가 인상적이네요.
SaturnV라는 전 세계에서 가장 큰 기업용 AI Datacenter도 소개했는데, 무려 1500개의 DGX 노드들과 12600개의 GPU, 56MW 평균 전력량을 자랑하는 말 그대로 돈 놓고 돈 먹는(?) 괴물 데이터센터입니다. 투자된 액수가 상상이 안될 정도로 정말 거대하네요. 더 나아가서 DGX SuperPod를 소개했는데, 잘은 모르겠으나 기업별로 최적화된 작은 데이터센터급 설비를 일컫는 것 같습니다. modular & scalable GPU architecture로 건설에 3주 가량이 소요되고 optimized for compute, networking, storage and software이라는 언급과 함께 Integrated fully optimized software stacks라는걸 보니 CUDA 생태계의 여러 소프트웨어를 탑재한 채 데이터 분석이나 서버 호스팅 업무에 투입 가능한 미니 데이터센터를 구축하기 위한 최소 단위인가 봅니다. 국내에서는 현대 모비스가 이 DGX superpod를 이용해 데이터센터를 구축할 예정이라네요. RTX server pod라는 것도 있는데, DGX가 비싸면 이거 사라라는 의미겠죠.
Jetson Nano와 ISAAC openSDK에 대한 소개도 있었습니다. 화질이 안좋아 사진은 따로 첨부하지 않았습니다만 Jetson Nano는 대부분 아시다시피 소형 CUDA processing unit이죠. 저는 ISAAC이라는 SDK가 생소했는데, 유저가 직접 학습시킬 수 있는 스마트 로봇 개발용 SDK라고 합니다. 즉 Jetson에 ISAAC을 설치하면 자신만의 로봇을 학습시킬 수 있게 되는 것이죠. 실제 환경뿐 아니라 simulated 환경에서도 학습이 가능하다고 합니다. 현재 SDK는 무료로 공개되어 있고, Jetson은 99달러에 구입이 가능하다고 하네요. 구미가 당기는 기기가 아닐 수 없습니다.
금융 분야에서도 NVIDIA는 결코 빠질 수 없습니다. Hedge fund와 같은 금융 분야에서 파이썬 알고리즘을 가속하기 위한 컴퓨팅 파워를 제공하고 있는데, DGX-2를 사용하면 20개의 클라우드 노드들에 비해 6천배의 성능 효과를 볼 수 있다고 합니다만….제가 이 부분에서 잠깐 졸아서 확실하지 않습니다. 그냥 정말 대단히 빨라졌구나, 정도로만 읽어 주시면 감사하겠습니다. 또한 사기(Fraud)와 같은 이상거래 탐지에도 자사의 T4 Gpu를 사용한다는 등 여느 키노트 세션들과 마찬가지로 자랑의 자랑이 이어졌습니다. 그럼에도 불구하고 트렌드를 알 수 있던 좋은 기회였습니다.
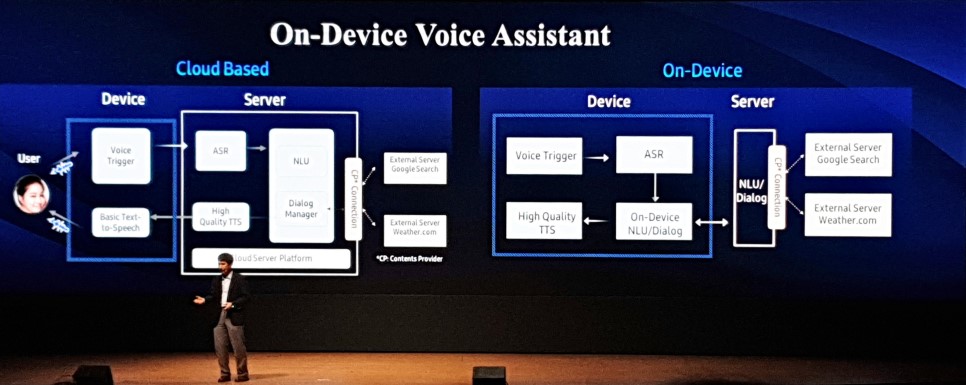

이어지는 삼성 종합기술원의 심은수님 세션에서는 On device AI라는 주제로 이야기가 진행되었습니다. 삼성이 AI 개발을 해온 것은 다들 아시겠지만 어떤 연구들을 해 왔는가는 베일에 가려져 있었죠. 오늘 세션을 통해 어렴풋이 그 속을 들여다볼 수 있었습니다. 삼성 종합기술원에서는 AI, Computing platform 두 분야에서 연구를 진행중입니다. AI 분야에서는 ML, CV, NLP, 그리고 특이하게 반도체 및 material design automation을 연구하고 있다고 합니다. Computing platform 분야에서는 요새 뜨거운 감자인 NPU(Neural processing unit)와 HPC, 보안과 같은 부문에서 연구를 진행하고 있다네요. 전세계에 지사가 있다고 합니다.
이날 강연의 핵심은 클라우드에서 온디바이스로의 전환이란 토픽이었습니다. 기존의 AI 서비스들은 클라우드 기반으로 돌아가 왔으나 폭증하는 AI 수요를 감당하기 어렵기도 하고 개인정보 이슈에 휘청일 수 있어 발빠르게 On-device로의 전환을 하고 있다는 내용이었습니다. 영화 Her 속 인공지능 여주인공, 사만다 이던가요? 아무튼 그 정도 수준이 삼성이 생각하는 AI의 궁극적인 수준이라고 합니다. 그러나 그 정도 수준에 도달하기 위해서 개인화가 필요하며, 기존의 AI들은 개인과 상관없이 많은 사람들의 데이터를 모아 일반화하는 데에 초점을 맞췄으므로 멍청했던 것이 사실입니다. 따라서 똑똑해지기 위해서는 개인 정보를 많이 학습해야 하며, 이것을 클라우드에서 학습을 하게 되면 결코 개인정보 보호 이슈에서 자유로울 수 없다는 것이죠. 온디바이스로 제공되는 어플리케이션은 Samsung home, Bixby가 될 것이라고 합니다.
이후로는 다른 연구들에 대해서 소개하는 시간이 이어졌습니다. Real time translation, Face recognition뿐만 아니라 온디바이스에서 신경망을 돌리기 위해 핵심이라고 할 수 있는 배터리 소모량을 줄이기 위해 최적화를 수행하는 연구에 대한 소개도 있었습니다. precision을 8비트까지 줄여 스마트워치 등의 작은 사이즈에서도 대응하게끔 노력 중인가봅니다. CNN은 사실 8비트 수준으로 줄여도 꽤 로버스트하며, 아직 이 분야는 학계에서 연구가 이루어지고 있다네요. precision을 낮춰 압축을 수행할 때 압축에 대한 파라미터 자체를 학습해 네트워크별 최적화된 압축을 수행하는 연구도 있죠.
그리고 컴퓨팅 파워는 쭉쭉 올라가는 반면 메모리에서 데이터를 읽어오는 bandwith가 빠르게 증가하지 않는다는 문제도 지적하며, 데이터를 읽어오는 병목 때문에 프로세서가 메모리를 기다리는 문제가 발생함에 따라 주어진 프로세싱 파워만큼 전체 성능이 올라가지 않는 이슈에 대해서도 이야기했습니다. CNN 계열의 네트워크는 컴퓨팅 파워가 올라갈수록 강력해지므로, 데이터가 메모리를 왔다갔다하지 말고 같이 두자(?)는 In-memory computing도 연구하고 있다고 하셨는데… 이 분야는 제 분야가 아니라 흘려 들었습니다. 이후 Infernence를 하며 learning도 동시에 수행하는 In-device learning에 대한 소개도 이어졌는데, 궁극적인 AI는 쓰면 쓸수록 똑똑해져야 한다는 것이 핵심 컨셉입니다. 새로운 데이터로 모델을 업데이트하되 온디바이스에서 수행하고 싶다는 것이죠. 구글에서도 2년여 전쯤부터 이 분야에 꽤 투자하고 있습니다.
현재의 Neural Network 학습 매커니즘은 새 것을 가르치면 앞의 기억을 까먹는 문제가 존재합니다. 너무 깊은 네트워크가 잘 작동하지 않는 주된 이유이기도 하죠. 이는 회사에서 모델을 만들어놓고 사용자 폰으로 보낸 다음 사용자 데이터로 학습을 하며 일반화되어 있던 오리지널 모델이 사용자 편향적인 모델로 변화할 수 있음을 의미합니다. 그래서 semi-supervised learning이나 life-long learning 분야에 대한 연구도 수행하고 있다네요.


원노트에 실컷 대여섯개 정도 강연 내용들을 받아적어오긴 했는데, 블로그에 올리자니 정리가 대단히 귀찮네요 ㅠㅠ
아무튼 최신 트렌드와 업계 흐름을 느낄 수 있었던 아주 좋은 기회였습니다. 근래들어 느끼지만 AI 연구는 점점 개인의 영역을 떠나는 것 같습니다. 몇년 전부터 예견되어 온 일이기도 하지만 BERT뿐만 아니라 BERT를 능가하는 XLNet과 같은 SOTA 논문들은 어마어마한 대수의 장비가 투입되죠. BERT 자체로도 대단히 거대한 연구였는데 자신들의 연구를 이듬해인 올해 또한번 뒤집는 구글브레인의 연구를 보며 한편으로 위축되는것도 사실입니다. 사실 제가 속한 연구실이 AI 전문 연구실이 아니다보니 저 혼자 스스로 공부하고 개발하는 실정인데, 이런 컨퍼런스나 스터디 그룹을 통해 교류하는 방법 말고 뾰족한 수가 달리 없는 것 같습니다. 회사에서 최고의 복지는 최고의 동료라고, 좋은 동료를 만날 수 있도록 이런 행사를 통해 업계에 촉각을 세우고 계속 공부하는 수밖에 없는 것 같습니다.