[NVIDIA AI Conference 정리] Tensorcore를 이용한 딥러닝 학습 가속을 쉽게 하는 방법
![[NVIDIA AI Conference 정리] Tensorcore를 이용한 딥러닝 학습 가속을 쉽게 하는 방법](/assets/img/devlog/event/NVIDIA_AI_Conf_Sessions/Getting_more_DL_Training_Acceleration_using_Tensor_Cores_and_AMP/1.png)
본 글은 2019년 7월 2일 NVIDIA AI Conference 행사 중 한재근 과장님께서 ‘Tensor Core를 이용한 딥러닝 학습 가속을 쉽게 하는 방법 (Getting more DL Training Acceleration using Tensor Cores and AMP)’이라는 제목으로 진행하신 강연을 정리한 글입니다. 원본 내용과 차이가 있을 수 있으니 행사 공식 슬라이드를 참고하시기 바랍니다.
Tensor Core에 대한 설명
▲ Volta, Turing 아키텍쳐에서 사용 가능하며 각 FP16 엘리먼트에 대해 연산한 후 FP32로 합치는 식으로 작동.
- 단정밀도를 사용하므로 파라미터 사이즈가 줄어들어 메모리 사용량이 줄어듬. 즉 두 배의 데이터를 처리할 수 있게 됨.
- 모델의 퍼포먼스를 높이기 위해 FP16을 사용하면 FP32 대비 x8의 연산처리량(throughput), x2의 메모리 처리량, 1/2의 메모리 사용량 효과를 볼 수 있음.
Mixed Precision Training이란?
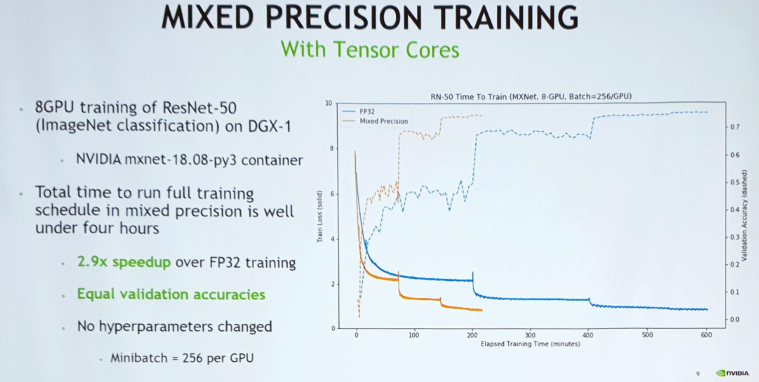
▲ MP는 연산속도와 정확도(accuracy) 사이의 트레이트오프 밸런스를 맞추기 위한 방법
- FP16(16 bit floating point)은 speed, scale을 위해 사용하고 task-specific accuracy 유지를 위해 FP32를 섞어 쓰는 것.
- Full precision과 비교해서 손해를 보지 않는 정도로 최대한 FP16을 쓰되 hyperparameter는 건드리지 않게끔 해야 함.
- 기존에는 MP training(Mixed precision training)을 하면 acc가 망가지는것이 아닌가에 대한 걱정이 있었으나 그렇지는 않은 모양.
- TF에서 MP를 사용했더니 3배의 속도 향상이 있었지만 사용하기 어려워 NVIDIA에서 Tensorcore에 AMP(Automatic Mixed Precision)을 추가.
- 모델 구성에 따라 Tensorcore를 사용하는 비중이 높아질수록 훈련 성능이 올라가며, acc면에서도 학습이 잘 되는 것을 확인 가능.
Mixed Precision is General Purpose
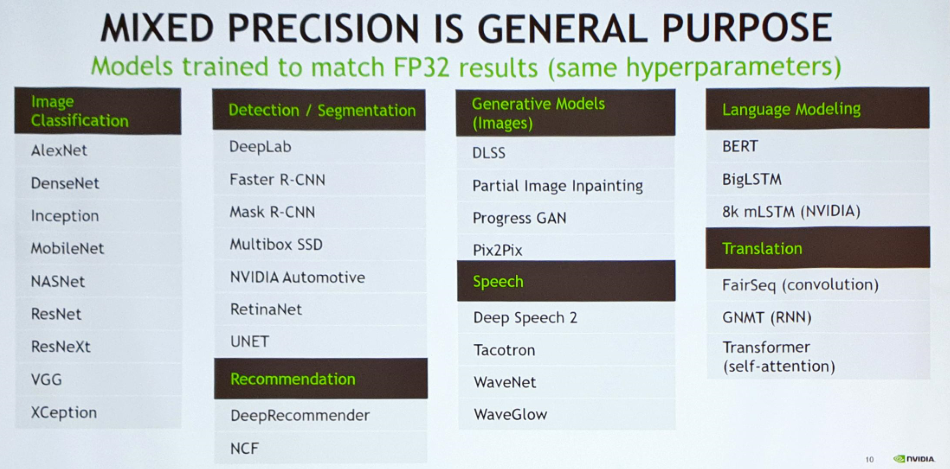
▲ MP를 적용 가능한 다양한 태스크 목록
NVIDIA 깃헙에 MP를 적용한 많은 예제 코드들이 올라와 있음.
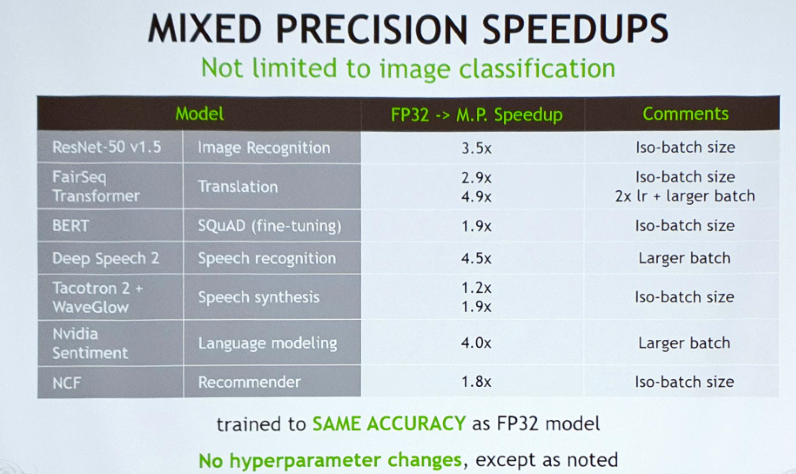
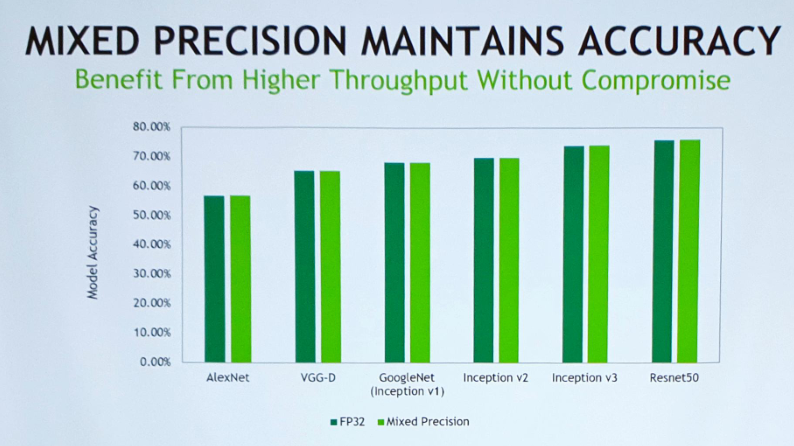
▲ 모델을 새로 짜지 않고 기술적으로 몇 부분만 고쳤음에도 같은 acc를 보인다.
MP Technical guide

▲ MP를 적용하기 위한 세 가지 방법
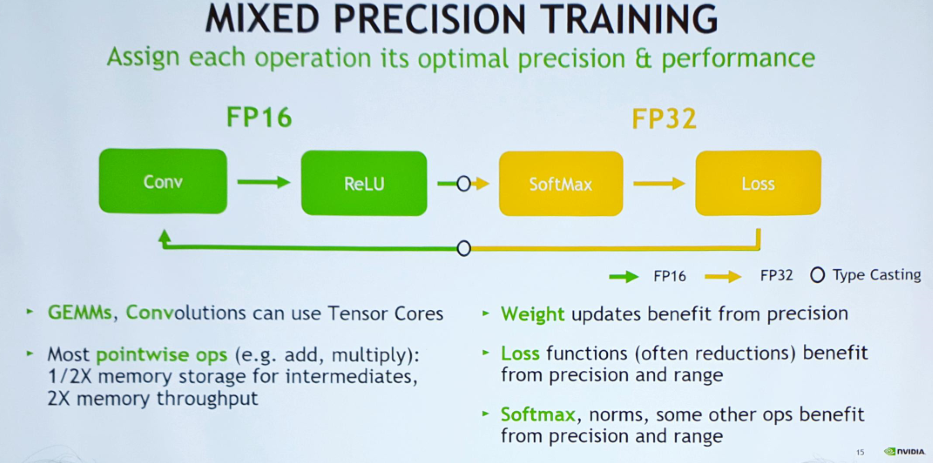
▲ 반정밀도로 떨어뜨리되 합치는 부분에서 단정밀도로 돌려 놓아야 함.
- 특정 연산(GEMMs, Convolution 등등)은 TensorCore의 도움을 받되 뒷단의 Softmax나 loss 연산 부분은 acc 유지에 중요한 역할을 하므로 FP32 유지 필수.
- weight는 single precision(단정밀도)을 유지하지만 back-propagation은 half-precision으로 수행
- single과 half를 섞어 쓰기 때문에 mixed precision training이라고 부름.
Concept of AMP

- Mixed Precision 적용을 더 편하게 수행할 수 있도록 도와주는 것이 AMP(Automated Mixed Precision)
- single->half로 바꾸는 부분이라던지 앞의 입력이 single/half인지 판단하는 부분을 자동으로 해 줌.
- 반정밀도로 떨어뜨리면 gradient가 vanishing할 수 있으므로 loss scaling도 자동으로 해준다(와우…). 단 loss scaling 수치는 hyperparameter이므로 테스트해보고 결정할것.
- Automatic casting : 웬만한 상용 프레임워크(TF, MXNET, Pytorch)들은 Tensor 연산에 대한 expressions가 잘 정의되어 있어 TensorCore를 적용하기 편함.
- 기존에는 네트워크마다 Tensorcore를 적용해보고 적용이 어려우면 사용하지 못했는데 이제는 안정적인 사용이 가능
Master weight를 single precision으로 유지하는 것이 핵심으로, acc 유지에 매우 중요한 역할.

단순히 precision을 다운하면 FP16 이 표현 가능한 범위의 한계로 인해 loss scale 표현에 문제가 생기고, 이로 인해 weight나 gradient가 0으로 바뀔 수 있음.
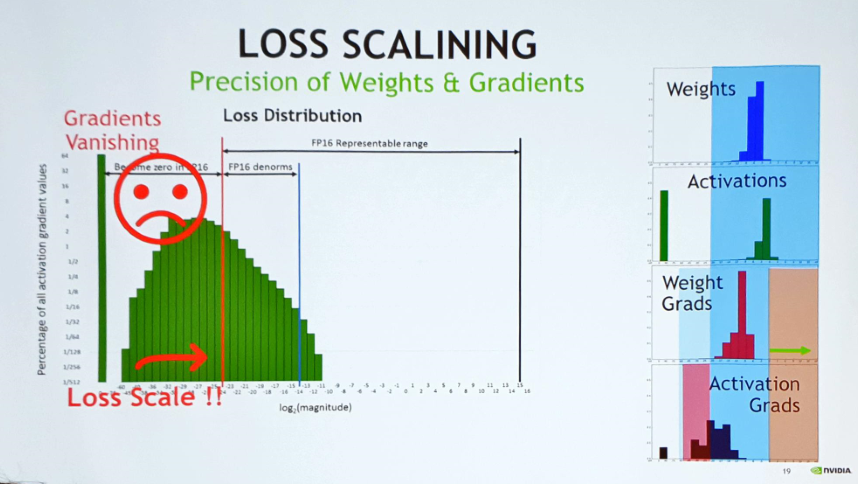
- 따라서 weight는 어쩔 수 없이 single precision으로 유지해야 함. 그래서 shift연산을 해서 값을 올려줌
precision마다 최대 크기가 다르기 때문에, 즉 FP16의 최대값이 FP32대비 작기 때문에 shift연산 시 오버플로우를 조심해야 한다. (그러나 이마저도 자동으로 해 줌)


Getting started on AMP
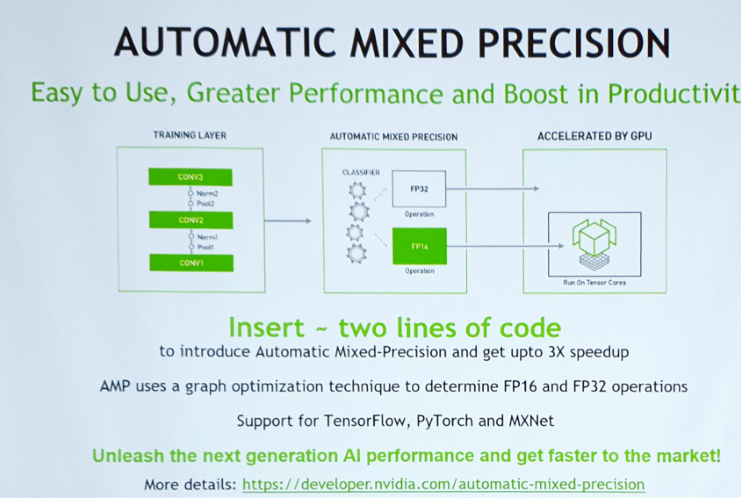
▲ 코드 두어줄 정도 추가하면 쓸 수 있도록 업데이트를 했다고 함. (Keras는 아직 개발중)


▲ Tensorflow에서 AMP 사용하기
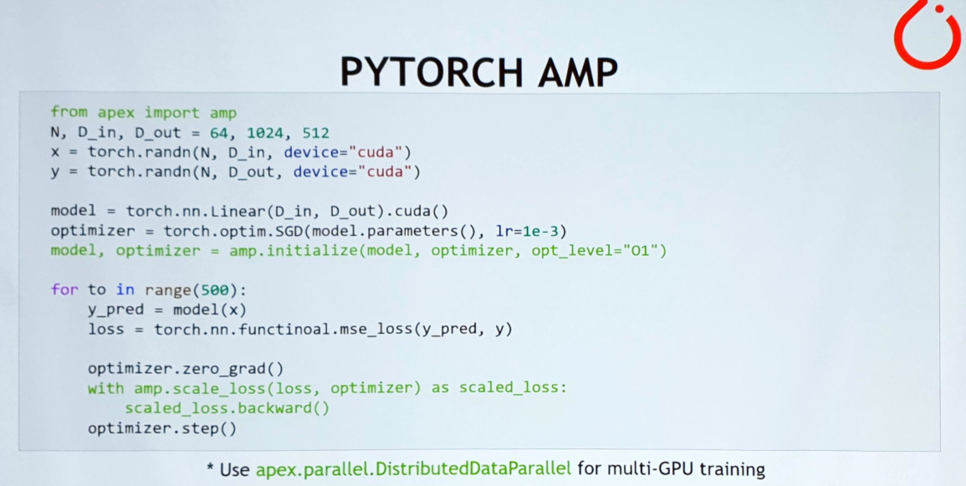

▲ (좌) 파이토치에서 AMP를 사용해 트레이닝하는 예제,
(우) 파이토치에서 Optimization level 설정하는 방법 및 장단점 소개

▲ MXNET에서 AMP를 사용하는 예제 코드
Performance guide of AMP

- GPU 하드웨어 특성상 32개의 연산을 묶어서 처리하며, 그래서 8의 배수로 맞춰 주면 가장 최적의 성능이 나온다고 함.
- VGG같이 사이즈가 3x3이라 애매할 경우는 패딩을 넣어서 돌림(8배수로 바꿔 넣으면 성능이 좋게 나오는 것을 확인 가능)
- 반정밀도를 사용하면 배치 사이즈를 두 배로 늘릴 수 있음.
텐서코어를 잘 사용하고 있는지 확인할 수 있는 방법 :
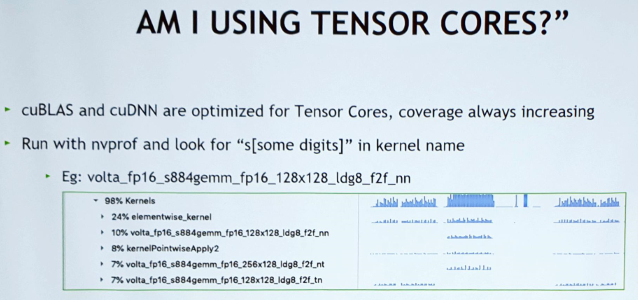
Tensorcore를 이용해 BERT모델 돌려보기 :

▲ (좌 - BERT FP32) 맨 왼쪽 패널에서 GPU kernel에 로드된 API list를 확인 가능, 빨간 글자 부분에서 실행 시간도 확인 가능.
(우 -B ERT FP16) 맨 왼쪽 패널에서 Tensor cores API가 커널에 로드된 것을 확인 가능하며 실행 시간이 2.1배 빨라짐을 확인 가능.
Additional Resources


▲ 다양한 모델들에 AMP를 적용한 예제 코드들을 제공.

▲ TF, Pytorch, MXNet에서 Tensorcore 활성화하기

▲ GTC Session recordings 2019에 디버깅하는 부분까지 포함해 알려준다고 함.
세션 요약
