(Event/Seminar후기) 건양대학교 Health Datathon 2019 유방암 검진대회에 참가했습니다!

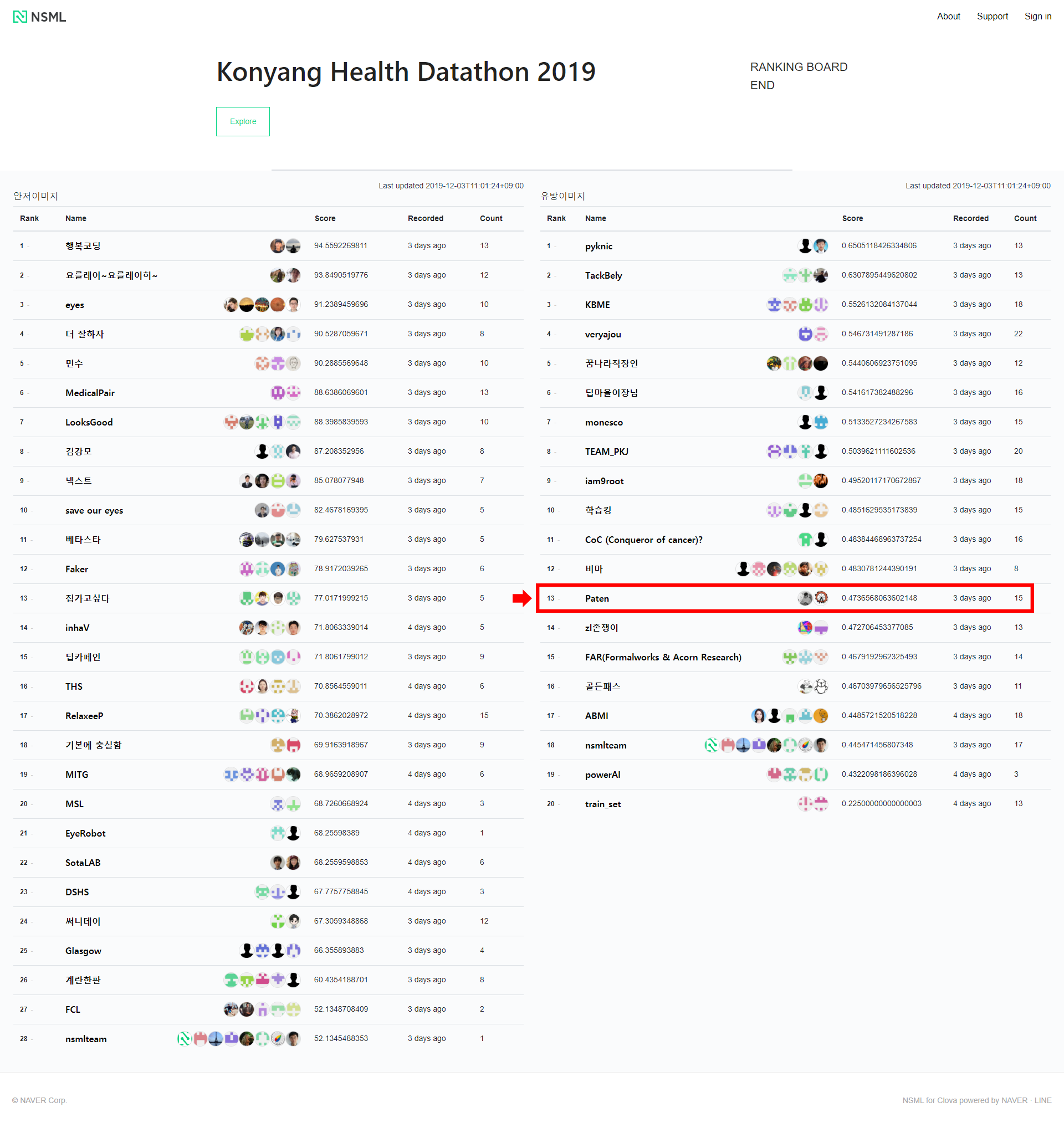
지난 11월 29일 개최된 Konyang Health Datathon 2019에 다녀왔습니다! 저희 팀 Paten은 유방암 검진 종목에 참가해 13등을 기록했습니다.

지난 11월 29일 개최된 Konyang Health Datathon 2019에 다녀왔습니다! 저희 팀 Paten은 유방암 검진 종목에 참가해 13등을 기록했습니다. F1 Score 0.473을 기록해 다소 처참하지만 중간에 발생했던 다양한 이슈들을 유연하게 대처하는 방법을 알아 온 것에 만족하려고 합니다. 대회 시작 전 2주일여 간 빡세게 도메인 지식을 습득하고 저희 팀만의 베이스라인 코드를 짜며 여러모로 준비를 많이 해 갔는데, 준비한 것의 절반도 채 못 보여주고 나와 너무 아쉬운 대회였습니다.

1등 팀의 솔루션이 충격적일 정도로 단순해서 대회가 끝나고 후유증이 상당히 심했었네요. 순위권에 대한 욕심이 너무 과해도 일을 망친다는 사실을 새삼 깨달은 소중한 경험이었습니다 ㅠㅠ
Pre-trained model을 사용할 수 없는 여파가 커서인지 1등 팀도 정확도가 0.7을 넘지 못했습니다.
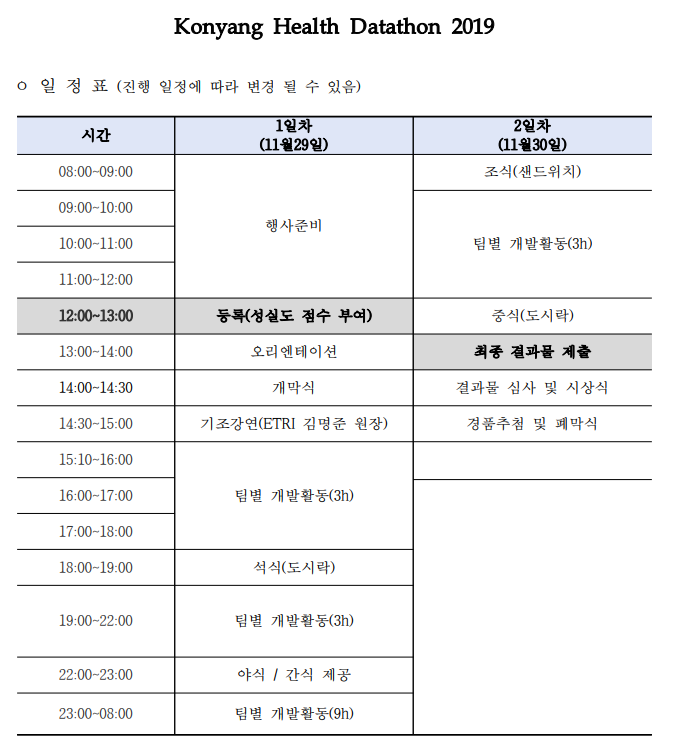
대회는 무박 2일간 건양대학교 대전캠퍼스 의과대학 명곡홀에서 진행되었습니다. 병원 건물 증축 공사가 진행 중인지 대학 건물 곳곳이 공사판이라 대회 진행 장소를 찾기가 좀 어려웠네요. 현수막과 안내 팻말도 명곡홀 근처로 가야 드문드문 보여서 네이버 지도의 힘을 많이 빌려 도착했습니다.



대회 시작에 앞서, 각 종목별로 의사 선생님들께서 간단히 안저와 유방 X-RAY 영상에 대한 소개를 해 주셨습니다. 이후 ETRI 김명준 원장님의 기조 강연이 이어졌는데, 개발자 분들이 듣기엔 다소 지루한 내용들이라 다들 큰 호응은 없으시더라구요.
뭔가 형식적인 대회라는 느낌을 지울 수 없었던 것이 개막식에 국민의례를 했다는 점입니다. 개발 대회에서 국민의례에 애국가 제창까지 한 경험이 많지 않아 신기했습니다.


기조 강연까지 모두 듣고 난 후 NSML 서버가 열리고 대회가 정식으로 시작되었습니다. 대회의 종목이 안저 영상 분류와 유방 영상 분류 두 종류로 구분되었기 때문에, 자리 배치를 종목 단위로 섞어서 해 주셨습니다. 팀 단위로 책상을 모아 자리를 구성해 주는 다른 대회와는 다른 방식이라 조금 낯설었네요.
이번 대회는 스탭 분들이 대단히 친절했으나…대회는 불친절한 부분이 없잖아 있었습니다. 대회 공식 페이지에 pre-trained model 사용 가능 여부가 공지되지 않아 대회 시작 사흘 전쯤에 저희 팀은 따로 메일을 보내 세세히 체크했습니다. 주중이라도 공지가 되었으면 좋았겠지만, 대회 당일 개막식에 pre-trained model은 사용할 수 없다고 공지해 주시더라구요.
또한 원활히 돌아가는 베이스라인이 Keras로만 제공되어 상당히 고생했던 기억이 납니다. Pytorch 코드의 경우 F1-score가 0으로 계산되는 문제와 함께 Inference 시 계속 OOM 에러가 발생해서 해당 부분을 수정하는 데 많은 시간을 할애했습니다. 두 베이스라인의 기능이 동일하지 않았다는 점도 돌이켜 보니 속상한 부분이네요.
개발 이슈 뿐 아니라 데이터셋과 관련한 이야기도 사전에 돌았었습니다. 대회 주최측에서 미리 공개한 안저 샘플 이미지는 심지어 전문의가 봐도 의문을 제기하실 정도로 적절한 샘플인지 이야기가 좀 있었습니다. 캐글과는 달리 비공개 데이터로 진행되는 대회이다 보니 데이터를 보지 못한 채 눈을 가리고 학습을 진행해야 한다는 점도 특이했고요.
결론적으로 다음 날 대회 종료 후 뚜껑을 열어 보았을때 힘이 탁 빠질 수밖에 없었습니다. 1등팀 솔루션이 EfficientNet-b0 1000epoch 이었거든요. 패자의 변명이지만, 다양한 feature extraction 기법들을 테스트할 수 있는 시간이 주어지지 않아 사실 누가누가 빠르게 모델을 셋업하나 겨루는 대회 같았습니다.
우승팀 후기 정리
- 유방암 분류대회 1등팀(‘Pyknic’, 0.6505) 전략
- 모델: Keras EfficientNet-b0 1000epoch, No ensemble
- 이미지 사이즈: 256 X 256 (원본 데이터는 440 X 360)
- Augmentation strategies: center crop(254*254), vertical/horizontal flip, normalization(0~1)
- Optimization strategies: ADAM Optimizer, Lr 0.0001
- 유방암 분류대회 2등팀(‘TackBely’, 0.6307) 전략
- 모델: VggNet (60 epoch, batch_size 16, No Ensemble)
- Augmentation strategies: Standardization, flip
- 데이터셋 샘플링 : Random shuffle
- 안저 분류대회 1등팀(‘행복코딩’, 94.559, Naver Speech대회 참가경력 있음)
- 모델: Keras VGGNet 100 epoch
- 이미지 사이즈: 350 X 450으로 키워 진행
- 기타 특징
- 가우시안 필터 사용 안함: 이전 캐글 대회 우수팀 전략에 가우시안 필터를 사용하는 예시가 있었으나 오히려 성능이 좋지 않아 제거(이것이 성능하락 요인인지는 ablation study 필요)
- 이전 speech 대회에서 label smoothing을 적용해 본 결과 성능이 좋았던 경험이 있어 이번에도 적용해 봄. (ablation study 필요)
- 안저 분류대회 2등팀(‘요를레이 요를레이히’, 93.849)
- 모델: ResNet18, 34를 비롯 다양한 12개 모델의 결과물을 Average Ensemble(Soft voting)
- 이미지 사이즈: 모델에 따라 다양한 인풋 사이즈 적용
- Augmentation strategies: 이미지 crop은 적용하지 않았고, 가우시안 필터로 이미지 전처리
EfficientNet 1000에폭은 볼수록 충격적이네요. 저희는 준비해 간 코드를 거의 써보지 못하고 현장 이슈 때문에 부랴부랴 아침이 되어서야 XceptionNet을 이용해 중위권에 들 수 있었습니다. 이번 대회 저희 팀의 패인은 너무 욕심이 과했다는 점입니다. 대회가 끝나는 날 아침 우승팀 후기까지 모두 듣고 난 후 한동안 화가 머리 끝까지 나 그냥 멍때리며 앉아 있었습니다.


그래도 대회 중 경품으로 아이패드 에어에 당첨되서 나름의 수확(?)은 건져 왔네요. 이대로 끝내기는 많이 아쉽기 때문에, 저희 팀은 앞으로 대회 중 미처 사용하지 못한 코드들을 발전시켜 논문을 써 보려고 합니다.
올해는 너무 성급해서 잘 될 일도 오히려 그르친 케이스가 다소 많았던 것 같습니다. 내년에는 올해의 소중한 경험들을 바탕으로 보다 진지하고 차분히 대회에 임할 수 있을 것 같습니다.
이번 대회에서 느낀 점.
1. 대회 준비는 대회의 기간과 수준에 맞게 준비를 해야겠습니다. 너무 과한 준비는 오히려 안하느니만 못함을 다시 한번 깨달았습니다.
2. 데이터셋의 크기가 작을 땐 너무 깊은 모델을 사용하지 않아야 합니다. DenseNet, XceptionNet과 같이 무거운 네트워크들은 소규모 데이터셋에 대해 오버피팅의 가능성이 존재합니다.
3. 마찬가지 이유로, 과도한 앙상블 전략은 독이 될 수 있습니다.