(NN Methodology) PatchGAN Discriminator 뽀개기
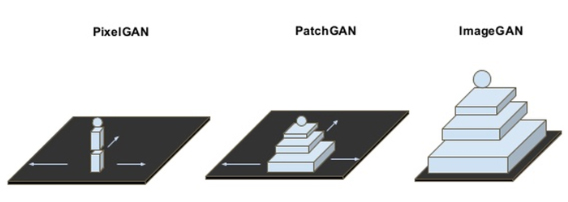
Image to image tralslation 분야를 공부하다보면 피해갈 수 없는 개념이 하나 등장합니다. 바로 PatchGAN Discriminator 구조인데요, Generator 부분이야 그렇다쳐도 patch 단위로 Discriminate를 한다는 컨셉이 그다지 직관적으로 와닿지는 않습니다. 이번 포스팅에서는 Pix2Pix와 같은 Image to image translation에서 빼놓으면 섭섭한 PatchGAN Discriminator 구조에 대해 알아보겠습니다.
본 글은 개인적으로 스터디하며 정리한 자료입니다. 간혹 레퍼런스를 찾지 못해 빈 곳이 있으므로 양해 부탁드립니다.
Image to image tralslation 분야를 공부하다보면 피해갈 수 없는 개념이 하나 등장합니다. 바로 PatchGAN Discriminator 구조인데요, Generator 부분이야 그렇다쳐도 patch 단위로 Discriminate를 한다는 컨셉이 그다지 직관적으로 와닿지는 않습니다. 이번 포스팅에서는 Pix2Pix와 같은 Image to image translation에서 빼놓으면 섭섭한 PatchGAN Discriminator 구조에 대해 알아보겠습니다.
Discriminator의 구조에 따른 GAN 네트워크의 구분
- 본문 맨 위 사진과 같이 PixelGAN은 1 x 1 patch에 대해 진위 여부를 확인하고, PatchGAN은 N x N 사이즈의 패치 영역에 대해 진위를 판단합니다.
- ImageGAN은 저희가 일반적으로 알고 있는 VanillaGAN처럼 전체 영역에 대해 진위 여부를 판단합니다.
기존 CNN 방식과 Conditional GAN의 차이점
| 기존 방식(CNN) | Conditional GANs |
|---|---|
| - 픽셀 단위의 classification 또는 regression으로 문제를 해결하고자 함. - 각 출력 픽셀들은 다른 픽셀들에 대해 서로 독립적이라고 가정. - Unstructured한 출력 공간의 개념을 갖고 있음. | - Structured loss를 사용하며, 즉 주어진 목표 이미지와 출력의 다름에 대해 Penalize한다. - Discriminator로 PatchGAN 구조를 자주 사용한다. - 모델에 추가적인 정보를 줌으로서 데이터를 만드는 과정을 지시할 수 있다. |
- Loss를 최소화하기 위한 방법으로 유클리디안 거리(L2 distance)를 사용하게 되면 모든 출력의 평균을 최소화하므로 흐린 결과물이 나오게 됩니다.
- 따라서 출력 이미지를 현실과 구분할 수 없도록 하면서도 목적에 맞게 loss function을 자동으로 학습하게끔 하는 것이 Conditional GAN의 목표입니다.
PatchGAN이란?
- PatchGAN은 전체 영역이 아니라 특정 크기의 patch 단위로 Generator가 만든 이미지의 진위 여부를 판단하며, Markovian Discriminator, Local-patch Disctiminator이라고 부르기도 합니다.
- 즉 correlation 관계가 유지되는 범위에 해당되는 적절한 크기의 patch 사이즈를 정하고, 그 패치들이 대부분 진짜인 방향으로 학습이 진행됩니다.
- Patch size는 전체 이미지 크기 및 영상 전체에서 특정 픽셀과 다른 픽셀들 간의 연관 관계가 존재하는 적절한 범위를 포함해야 하기 때문에 hyperparameter이라고 볼 수 있습니다.
- 기존 GAN에서 Discriminator는 Generator가 만들어준 입력 데이터(이미지) 전부를 보고 Real/Fake 여부를 판단합니다. 따라서 Generator는 Discriminator를 속이기 위해 데이터의 일부 특징을 과장하려는 경향을 보입니다.
- G는 사람이 보는 이미지 퀄리티 여부와 상관없이 D를 잘 속이는 방향으로만 학습을 하게 되고, 이로 인해 결과 이미지에 블러가 끼어 나타나게 됩니다.
- 따라서 보통 전체 이미지에 대한 Low frequency 성분을 L-1 regularization term을 통해 파악한 후 High frequency 성분을 잘 보는 PatchGAN D와 결합하는 식(summation)으로 Discriminator의 loss를 구성합니다.
- PatchGAN은 patch의 직경보다 더 멀리 있는 픽셀들은 서로 independent하다는 가정을 깔고 가므로 이미지를 하나의 MRF(Markov Random Field)로 모델링할 수 있게 됩니다.
- MRF는 무방향 확률그래프(Undirected graph) 모델로서 베이지안 모델링(Bayesian modeling)을 통해 이미지를 분석하는 데 사용됩니다.
- MRF는 무조건 Bayesian approach로 모델링되며, Markov assuption(마르코프 가정)을 갖는 Random Field를 의미합니다. 즉 Random Field간에 시간이 아닌 지역적인 마르코프 속성이 있어서 바로 근처의 주변 픽셀만 고려하고 나머지는 고려하지 않습니다.
- 마르코프 모델이란 마르코프 가정이 성립되는 시스템을 의미합니다.
- 1차 마르코프 연쇄 : 한 상태에서 다른 상태로 변할 확률이 현재의 상태에만 의존하는 모델
- 1차 마르코프 가정 : 시간 n에서 어떤 사건이 관측될 확률은 n-1에서의 관측 결과인 qn-1에만 의존한다는 가정입니다.
- 한 부분의 데이터를 알아내기 위해 전체 데이터를 보고 판단하는 것이 아닌, 이웃하고 있는 데이터들과의 관계를 파악해 판단합니다.
- 이미지의 relevant한 통계적 종속성(statistical dependencies)이 Local level에 존재한다고 가정하고 로컬 이미지 패치의 likelihood를 학습합니다. (「Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis」 ‘Introduction’ 내용 중 발췌. 이 논문에서 NxN patches를 사용하는 컨셉이 처음으로 제안되었으나 D가 아닌 생성 모델에만 국한되어 있음.)
- MRF는 Image restoration, Texture analysis, Image segmentation, Image labeling, Edge detection, Object recognition 등의 분야에 사용됩니다.
PatchGAN을 사용하는 주된 이유
- 전체 이미지가 아니라 작은 이미지 패치 단위에 대해 sliding window가 지나가며 연산을 수행하므로 파라미터 개수가 훨씬 작아집니다. 이로 인해 연산 속도가 더 빨라지고, 전체 이미지 크기에 영향을 받지 않아 구조적 관점에서 유연성을 보입니다.
- Discriminator의 네트워크 크기를 줄일 수 있게 됩니다. Receptive Field의 크기를 늘리려면 Kernel이 커지거나 레이어를 더 쌓아 네트워크가 깊어져야 하지만 마냥 깊다고 좋은 성능을 내지는 않습니다.
- 전체 이미지 크기에 영향을 받지 않고 네트워크가 어느 정도 가벼워질 수 있기 때문에 Pix2Pix 이후로 나오는 Img2img translation 논문들은 PatchGAN 구조를 상당히 많이 차용하게 됩니다.
- low frequency에 대해 학습하는 L1 regularization term과 local 영역에서 sharpen한 디테일, 즉 high frequency 영역(엣지)에 대해 patch 단위로 학습함으로서 두 방식의 장점을 모두 취할 수 있게 됩니다.
PatchGAN 적용 예시(Pix2Pix)
- PatchGAN의 patch size는 Discriminator가 가진 convolution layers에 의해 결정되는 Receptive field size에 따라 결정됩니다. 즉 PatchGAN D는 G가 만든 이미지 일부를 Crop하는 것이 아닙니다.
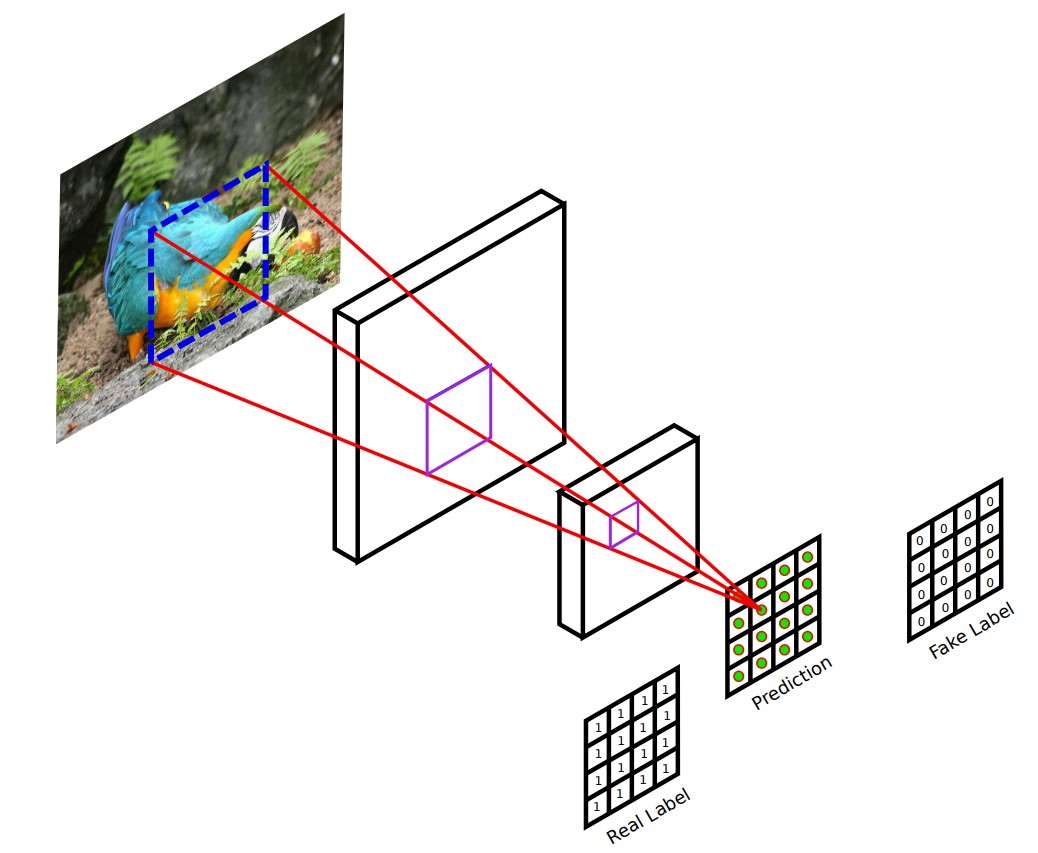
Pix2Pix 논문에서는 256 x 256 크기의 입력 영상과 입력 영상을 G에 넣어 만든 Fake 256 x 256 이미지를 concat한 후 최종적으로 30 x 30 x 1 크기의 feature map을 얻어냅니다. 이 feature map의 1픽셀은 입력 영상에 대한 70 x 70 사이즈의 Receptive field에 해당합니다.
▲ 출처 : Patch-Based Image Inpainting with Generative Adversarial Networks {:.figcaption}
- 이후 30 x 30 x 1 feature map의 모든 값을 평균낸 후 Discriminator의 output으로 합니다. (‘We run this discriminator convolutionally across the image, averaging all responses to provide the ultimate output of D.’ - Pix2Pix 논문 3.2.2절)
- L1 loss를 사용함으로서 Generator는 Discriminator를 속이는 것 뿐만 아니라 정답 이미지(Ground Truth)와의 L1 distance를 줄이는 역할을 동시에 수행하게 됩니다.
- Discriminator에 conditon이 들어가지 않으면, 즉 Generator가 Fake 이미지를 만들 때 본 condition을 Discriminator가 보지 않게 되면 input과 output의 mismatch를 따지지 않게 되므로 성능이 좋지 않습니다. 따라서 Pix2Pix는 condition이 G 뿐만 아니라 D에도 들어가게 됩니다.
Pix2Pix의 Optimization and Inference
- Optimization : Vanilla GAN의 optimization 방식을 따랐으며, D에 대해 Gradient Descent step 한번, G에 대해 Gradient Descent step 한번씩 번갈아 가며 학습합니다.
- Dropout과 Minibatch SGD를 적용했고, Adam을 사용했습니다.
- Inference : 테스트 단계에도 Dropout을 적용하고, test batch의 statistics를 적용한 batch normlaization을 사용했습니다. (일반적으로 다른 모델에서는 training batch의 staatistics를 사용합니다.)
- 이러한 방식은 instance normalization(batch size가 1~2와 같이 극도로 작은 경우 사용)과 같으며, Instance normalization: The missing ingredient for fast stylization 논문에서 제안된 바 있습니다. 이미지를 낮은 배치에서 생성할 때 효과적입니다.
- 배치 사이즈가 4일 때는 batch normalization을, 1일때는 instance normalization을 사용했습니다.
Receptive Field의 사이즈에 따른 퀄리티 차이
- Receptive field가 좁을수록(1x1, 16x16, 30x30 등등) 모델이 판단하는 영역에 한계가 존재하게 됩니다. (사람도 강아지나 고양이에 대해 너무 작은 이미지 조각을 보여주면 구분하지 못하는 것과 비슷합니다.)
- 모델이 판단하는 영역에 한계가 존재한다는 것은 즉 Discriminator가 잘 속게 됨을 의미하고, 따라서 퀄리티가 떨어지게 됩니다. RF 사이즈는 따라서 Discriminator 학습의 핵심이라고 할 수 있습니다.
- CycleGAN은 70, DiscoGAN은 94의 RF size를 갖고 있습니다. 단 CycleGAN의 경우 RF size가 커지면 학습이 불안정해지고 파라미터가 증가합니다.
- Receptive Field 사이즈를 계산하는 공식은 제 블로그의 Convolution output size와 RF(Receptive Field)사이즈 계산하기를 참고하셔도 좋고, Receptive Field Calculator에서 레이어 구조를 입력하시면 편하게 레이어별 RF size를 확인할 수 있습니다.
Reference
- LA Gatys at al, “Image style transfer using convolutional neural networks”, CVPR2016
- Alexei A. Efros et al, “Texture synthesis by non-parametric sampling”, ICCV 1999
- Alexei A. Efros et al, “Image quilting for texture synthesis and transfer”
- Chuan Li et al, “Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks”
- Chuan Li et al, “Combining markov random fields and convolutional neural networks for image synthesis”
- 라온피플 네이버 블로그 - pix2pix 3
- Conditional GAN 관점에서 바라본 pix2pix 네트워크 설명
- (한국어 논문리뷰 - kakalab) Image-to-image Translation with Conditional Adversarial Networks
- (한국어 논문리뷰 - navisphere) Image-to-Image Translation with Conditional Adversarial Networks
- Markov Random Field, MRF