(번역중) CVPR 2019의 Few-Shot Learning
본 글은 Medium Towards Data Science ‘Eli Schwartz’의 Few-Shot Learning in CVPR 2019를 번역한 글입니다.
본 글은 Medium Towards Data Science 'Eli Schwartz'의 글을 번역한 글입니다. 제 의견이 들어간 부분은 역주를 따로 달았습니다. (역자 : 이명규)
원문글 : Few-Shot Learning in CVPR 2019
요약) 이 글은 CVPR2019에서 공개된 모든 few-shot 학습 기법에 대해 요약한 글입니다. 아래 내용들은 저를 위해 메모했던 것들이기 때문에, 곧이곧대로 듣지 말아주십시오. 몇몇 논문들에 대해 저는 포스터 세션에서 저자들과 토론할 수 있는 특별한 시간을 가졌고, 일부는 제가 읽거나 훑어 본 것들입니다. 내용에 문제가 있다면 저에게 알려 주십시오.
Background(배경지식)
적은 수의 사진만 갖고 물체를 인식하는 문제는 최근들어 매우 핫합니다.(CVPR2018에서 네 편이었던 것이 올해 CVPR2019에서는 스무 편에 달합니다. ) 일반적으로 이 태스크는 학습 단계에서 많은 수의 카테고리를 갖고 있는 샘플들이 주어집니다. 이후 테스트 단계에서 새로운 카테고리(보통 5개)와 함께 카테고리당 ‘support set’이라고 부르는 1~5장 정도의 적은 샘플들, 그리고 쿼리 이미지들 또한 제공해 줍니다.
이어서 몇 가지 few-shot learning을 위한 방법들을 구분지어 소개해 보겠습니다. 사실 이 방법론들이 완벽하게 정의된 것은 아니며, 교집합이 존재합니다.
오래된 few-shot learning 방법들은 Metric learning에 기반합니다. metric learning의 목적은 동일한 카테고리의 이미지끼리는 가깝게, 다른 카테고리끼리는 멀리 떨어지도록 이미지를 임베딩 공간에 매핑하는 방법을 학습하는 것입니다. 처음보는 카테고리에도 이 방법이 잘 작동하기를 바라죠.
그러한 요구에 따라, Meta-learning 기법이 등장했습니다. 이 모델들은 최신 연구들과 엮여 있으며, 다양한 다른 분류기들이 support set을 위한 함수로서 사용됩니다. Meta-learning의 핵심 컨셉은 few-shot 이미지들에 오버피팅되지 않으면서도 새로운 문제에 작 적응하도록 모델의 하이퍼파라미터와 매개 변수를 찾는 것입니다.
이와 동시에 학습 데이터를 증강시키는 data augmentation 방법도 매우 인기가 있습니다. 이 방법은 사용 가능한 적은 장수의 샘플들을 통해 더 많은 샘플들을 생성할 수 있도록 (모델에 최적화된) data augmentation 기법을 학습합니다.
마지막으로, 의미론 기반 방법(semantics-based method) 또한 떠오르고 있습니다. 카테고리 이름, 설명 또는 속성만을 기준으로 하여 학습하는 zero-shot learning으로부터 영감을 얻은 이 방법은 시각적인 의미가 부족한 경우에 추가적으로 의미적 정보를 사용하면 도움이 될 수 있습니다.
Papers covered in this post
- Metric learning 분야
- Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning (Wenbin Li et al.)
- Few-Shot Learning with Localization in Realistic Settings (Davis Wertheimer et al.)
- Dense Classification and Implanting for Few-Shot Learning (Yann Lifchitz et al.)
- Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images (Junsik Kim et al.)
- Meta learning 분야
- Meta-Learning with Differentiable Convex Optimization (Kwonjoon Lee et al.)
- Edge-labeling Graph Neural Network for Few-shot Learning (Jongmin Kim et al.)
- Meta-Transfer Learning for Few-Shot Learning (Qianru Sun et al.)
- Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning (Spyros Gidaris et al.)
- Finding Task-Relevant Features for Few-Shot Learning by Category Traversal (Hongyang Li et al.)
- Data augmentation 분야
- LaSO: Label-Set Operations networks for multi-label few-shot learning (Amit Alfassy et al.)
- Few-Shot Learning via Saliency-guided Hallucination of Samples (Hongguang Zhang et al.)
- Spot and Learn: A Maximum-Entropy Patch Sampler for Few-Shot Image Classification (Wen-Hsuan Chu et al.)
- Image Deformation Meta-Networks for One-Shot Learning (Zitian Chen et al.)
- Semantics-based 분야
- Baby steps towards few-shot learning with multiple semantics (Eli Schwartz et al.)
- Generalized Zero- and Few-Shot Learning via Aligned Variational Autoencoders (Edgar Schönfeld et al.)
- TAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning (Xin Wang et al.)
- Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy (Aoxue Li et al.)
- Beyond recognition (인식 이외 다른 분야들을 위한 few-shot learning기법들)
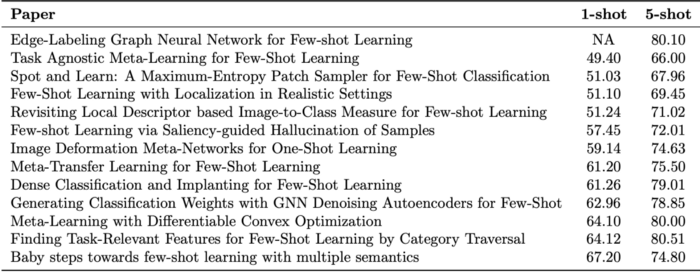
Performance on the mini-ImageNet benchmark
(포스트의 내용과) 연관성이 있는 이번 CVPR 논문들에 대해서 1-shot 성능순으로 정렬해 보았습니다.
Metric learning methods
§ Revisiting Local Descriptor based Image-to-Class Measure for Few-shot Learning, Li et. al
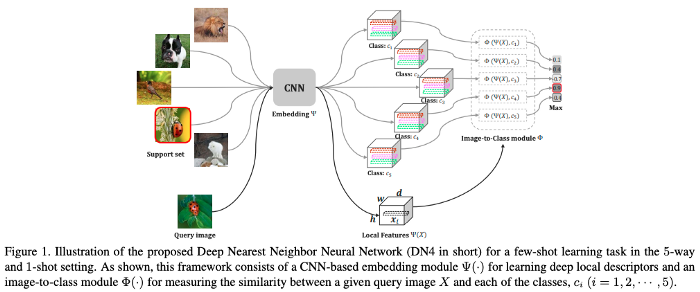
이 연구에서 저자들은 bag-of-word 시절 느낌이 들게 하는 local descriptors를 제안합니다. 그러나 features가 CNN으로부터 뽑힌다는 것과, 모든 것들이 end-to-end로 학습된다는 것이 차이점입니다. 논문의 결과는 벤치마크 결과의 아래쪽에 있습니다.
§ Few-Shot Learning with Localization in Realistic Settings, Wertheimer et. al
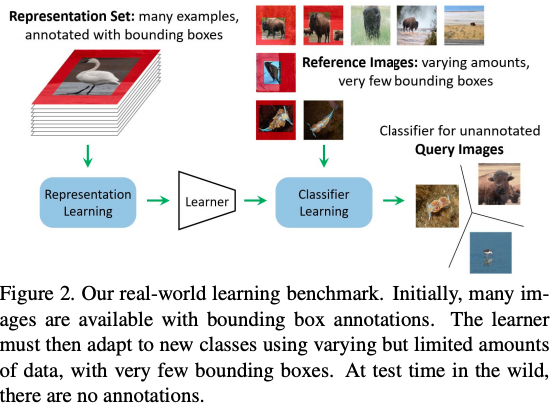
클래스 밸런스를 맞추기 위해 인위적으로 클래스 5개에 대해 테스트하는 few-shot benchmark 방식이 현실적이지 않다고 주장하는 이 논문의 저자들은 새로운 데이터셋과 벤치마크 방식을 제안했습니다. 저자들의 모델은 동시에 지역화(Localization) 및 분류(Classification)를 수행합니다. 그러나 단점은 주석이 달린 bounding box 데이터셋이 필요하다는 것입니다. 저자들의 연구에 사용된 분류기는 prototypical network들을 기반으로 하였으나 최종적으로 사용된 feature vectors는 모델에 통과된 전경과 배경의 vector representation을 연결(concat)한 것입니다.
§ Dense Classification and Implanting for Few-Shot Learning, Lifchitz et. al
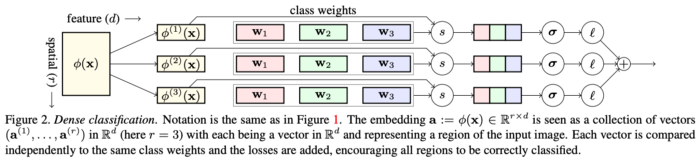
이 연구에서 분류(classification)는 조밀하게(densly) 수행됩니다. 모델의 끝부분에서 Global average pooling을 사용하지 않는 대신 모든 공간의 위치들에 대해 올바르게 분류되어야 합니다. 또한 테스트 타임 중 마지막 레이어 부분에서 fine-tuning을 하지 않는 대신 뉴런을 추가하고 미세 조정함으로써 각 계층을 넓힙니다. (추가된 레이어의 가중치만 학습하고 이전 뉴런들의 가중치는 고정합니다.)
§ Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images, Kim et. al.
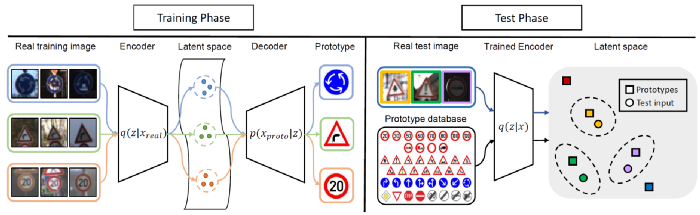
이 연구는 로고 또는 도로 표지판 분류를 다루는 one-shot(한장) 분류 문제를 다루고 있습니다. 이 연구에서는 그래픽 이미지(로고, 표지판과 같은)를 프로토타입(원형)으로 취급합니다. 이후 실제 현실의 로고, 표지판 이미지를 프로토타입 이미지에 매핑하는 meta-task를 학습해 좋은 representation을 만드는 방법을 학습합니다.
(역자주 : Variational prototyping encoder one shot learning with prototypical images 논문은 저자이신 김준식 님께서 7월 17일 T.TOC 최신논문 공유회에서 설명해 주신 바 있습니다. 해당 논문은 나라, 회사마다 심볼 디자인들이 미묘하게 다른 경우에 대해 모든 데이터셋을 모으기 어려운 문제를 지적하며 또한 대규모의 데이터를 모아도 모델을 완벽히 학습하는 데에 한계가 있다고 주장합니다. 또한 특정 클래스에 데이터들이 몰려 있고 나머지들은 few-shots라는 문제가 존재했으며, TT100k 데이터셋의 경우에도 다섯개 도시 인근에서 10만 장을 캡쳐했음에도 데이터를 많이 모으지 못했다고 합니다. 평가가 어려운 클래스들이 존재하는 제약사항이 있었고, 따라서 이 문제를 해결함으로서 광고, 표지판 이해, 교통 표지판 이해 등의 문제에 효율적으로 적용할 수 있다고 합니다. 훈련 과정에서는 고정된 클래스가 아닌 랜덤 클래스 샘플링 후 다른 클래스라는 가정을 두어 학습하며, 핵심은 대규모의 데이터셋에서 얼마나 일반화를 잘 해 내고 소량의 데이터셋에서 이렇게 학습한 knowledge가 빠르게 잘 적용되는지 확인하는 것이라고 합니다. 특이하게 Image to image translation 기법 기반으로 feature space를 잘 학습하고자 하였고, 저자들은 따라서 VPE, 즉 Varational prototyping encoder라는 VAE의 변형된 네트워크를 제안합니다.)
Meta-learning methods
§ Meta-Learning with Differentiable Convex Optimization, Lee et. al
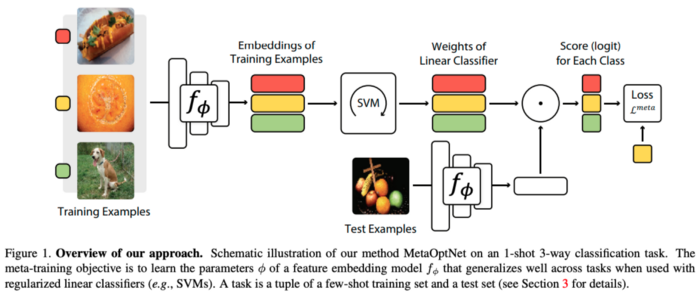
이 연구는 의미론적 정보(semantic information)을 사용하지 않는 방법들 중 최고의 벤치마크 결과를 보여 줍니다. SVM 분류기와 학습된 end-to-end 분류기를 결합해 강력한 백본망을 구성하였으며, 이 연구를 통해 저자들은 프로토타입 네트워크(Prototypical network)와 함께 자신들이 만든 백본망을 사용하는 것만으로 높은 정확도를 달성했습니다. SVM을 사용하면 성능이 더 좋아지는 것 또한 보여줍니다. 분류기의 인풋으로 들어가는 feature의 차원이 꽤 높게 유지되지만, SVM이 고차원 features를 더 잘 처리하기 때문에 성능이 부스팅된 것이 아닌가 싶습니다.
§ Edge-Labeling Graph Neural Network for Few-shot Learning, Kim et. al
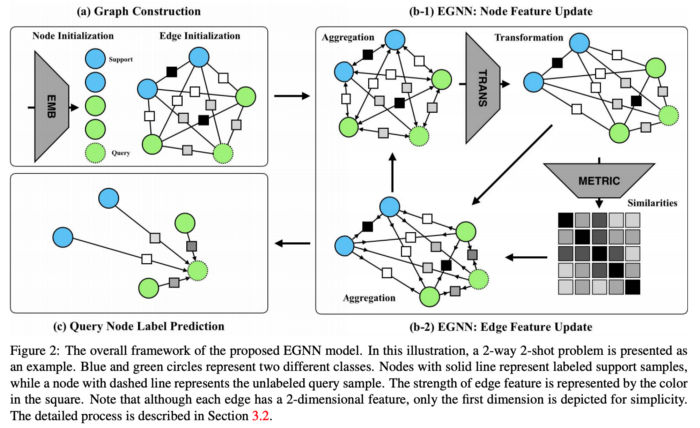
Graph Neural Network는 이전에도 few-shot learning에 여러 번 사용되었습니다. Graph Neural Network의 기본적인 아이디어는 각 이미지를 그래프의 노드로 표현하는 것이며, 노드들이 얼마나 유사한지에 따라 정보(node representation)가 전파됩니다. 일반적으로 분류 문제는 노드들(node representations)의 거리에 따라 암시적으로 수행되지만, 저자는 여기서 노드 사이의 유사성을 설명하는 explicit features per edge를 제안합니다. (역자 주 : 노드를 잇는 선을 edge라고 합니다.)
§ Task Agnostic Meta-Learning for Few-Shot Learning, Jamal et. al
이 연구에서는 메타 러닝된 모델이 과적합되는 것을 피하기 위해 예측된 결과에 규제 항(regularization term)을 적용합니다. 규제항은 예측된 결과가 더 높은 엔트로피(역자주 : 정보량)를 갖도록(즉 예측된 확률이 one-hot vector처럼 행동하지 않도록) 강제로 task들 간의 inequality를 낮게 하도록 합니다. 명백히 규제를 강력하게 하는 것이 few-shot 학습에 있어 중요하지만, 저는 직관적으로 이러한 feature regularization이 왜 바람직한지 와닿지 않습니다. 저자들은 MAML의 윗단에서 테스트를 수행하는 게 성능이 더 우수하다는 것을 보여 줬습니다. 아마 다른 방법들의 위에서 사용할 때에도 도움이 되는지 확인해 보는 것도 흥미로울 것 같습니다.
(역자주 : Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (2017)에서 소개된 MAML은 메타 러닝의 한 방법입니다. 메타 러닝의 요점은 일반적으로 여러 task에 대해 학습된 모델이 아주 적은 데이터만을 사용해서 새로운 task도 잘 수행할 수 있도록 새로운 모델을 학습하는 것이라 할 수 있습니다. 따라서 메타 러닝은 다음의 두 가지 방법으로 분류가 가능합니다. 먼저 meta-learner를 도입하여 기존 모델의 파라미터가 어떻게 업데이트되어야 하는지 학습하거나 두 번째, 좋은 weight initialization 지점을 사용함으로서 효율적인 학습이 가능케 합니다. 기존에는 meta-learner를 도입하는 방법이 더 많이 사용되어 왔으나 MAML은 이 중 후자에 속합니다. MAML은 classification, regression같은 지도학습 외에도 강화학습 등의 거의 모든 경사하강법이 응용된 학습 모델에 적용할 수 있다는 장점이 있습니다. https://jiminsun.github.io/2019-01-28/maml/ 를 참고해 주세요.)
§ Meta-Transfer Learning for Few-Shot Learning, Sun et. al
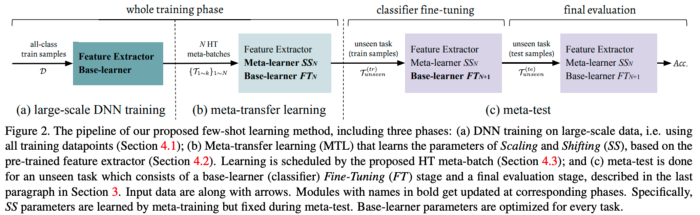
이 연구에는 두 가지 중요한 요소가 있습니다. 1. weight를 고정한 상태에서 레이어 당 scale과 shift만 학습되는 pre-trained model의 미세 조정(fine tuning), 2. Hard task mining이 그것입니다. 제가 MAML에 대해 잘못 알고 있는 게 아니라면 Batch normalization 레이어에 대해 fine-tuning을 적용합니다. 이것은 즉 scale과 shift만 학습하는 것과 같지 않습니까? Hard batch mining(이전 task에서 낮은 정확도를 가진 클래스들을 모아 task를 구성한 것)은 MAML의 윗단에서 적용할 때 효과적인 것으로 보입니다.
(이하 번역중입니다.)