(번역중) 시맨틱 세그멘테이션을 위한 딥러닝 알고리즘 리뷰

본 글은 Medium 유저 ‘Arthur Ouaknine’의 Review of Deep Learning Algorithms for Image Semantic Segmentation를 번역한 글입니다.
제 의견이 들어간 부분은 역주를 따로 달았습니다. (역자 : 이명규)
원문글 : Review of Deep Learning Algorithms for Image Semantic Segmentation
Intro(들어가며)

▲ stuff segmentation을 위한 COCO dataset 예시. (http://cocodataset.org/)
딥러닝 알고리즘들은 난이도가 증가함에도 불구하고 여러 컴퓨터 비전 문제들을 해결해 왔습니다. 이전 제 블로그 포스팅에서, 저는 많은 사람들에게 잘 알려진 Image Clasification과 Object Detection에 대해 소개한 적 있습니다. 이미지 세그멘테이션 문제에서는 이미지의 각 픽셀을 하나의 인스턴스로 분류하는데, 각 인스턴스(또는 카테고리)는 이미지에 존재하는 객체(도로, 하늘 등등)들과 대응됩니다. 이미지 세그멘테이션 작업은 장면 이해(Scene understanding)의 컨셉 중 하나입니다. 어떻게 딥러닝 모델이 시각적 컨텐츠에 존재하는 글로벌 컨텍스트를 더 잘 배울 수 있을까요?
객체 감지(Object detection) 작업(이하 ‘태스크’)은 복잡성 측면에 있어서 이미지 분류 태스크를 초과했습니다. 객체 감지 태스크는 이미지 안에 존재하는 개체 주위에 경계 상자(Bounding box)를 만들고 각 개체에 대해 분류 작업을 수행합니다. 대부분의 객체 감지 모델은 대부분의 객체 감지 모델은 앵커 상자(anchor box)와 proposal(역주 : Fast RCNN의 Region Proposal을 이야기하는 것 같습니다.)을 통해 객체 주위의 경계 상자를 검출합니다. 불행히도, 일부 모델은 이미지의 전체 맥락(context)을 고려할 수 있지만 주어진 정보 내에서도 작은 부분에 대해서만 분류 작업을 수행합니다. 따라서 이러한 모델들은 자신에게 주어진 장면을 완전히 이해할 수 없습니다.
장면(scene)을 이해하기 위해선 각 시각적 정보가 공간적 정보(spatial information)를 고려하면서 엔티티(여기서는 객체를 의미)와 연관될 필요가 있습니다. 이미지 또는 비디오로부터 동작(Keypoint detection, action recognition, video captioning, visual question answering 등등)을 모델이 이해하는 데 있어 몇 가지 도전적인 문제들이 생겨났으며, 모델이 환경에 대해 잘 이해할 수 있다면 더 많은 분야에서 도움이 되어 줄 것입니다. 예를 들어, 자율 주행 자동차는 주행중에 있어서 도로변을 높은 정밀도로 인식하도록 해야 합니다. 로봇 공학에서 생산에 사용되는 기계는 물체의 정확한 모양을 파악함으로서 물체를 어떻게 잡는지, 두 개의 다른 조각을 어떻게 조립하는지 이해해야 합니다.
이 블로그 포스트에서는 의미적 이미지 분할화(이하 Image Semantic Segmentation) 문제에 대한 기존의 최신 모델 아키텍쳐들에 대해 설명할 것입니다. 연구자들은 매년 달라지는 다양한 데이터셋(PASCAL, VOC, PASCAL Context, COCO, Cityscapes)들을 사용해 알고리즘을 테스트하고 다양한 평가 메트릭(metric)을 사용해 알고리즘을 평가합니다. 따라서 논문에 인용되어 있는 성능 지표 그 자체는 직접적으로 끼리끼리 비교해 보기가 어렵습니다. 또한 각 알고리즘들의 결과는 사전 훈련된 최상위 네트워크(pretrained backbone)에 따라 달라지며, 본 포스트에 게시된 평가 결과는 각 논문들에서 그들의 테스트셋을 통해 얻은 최고 점수입니다.
데이터셋 및 평가 지표(Datasets and Metrics)
PASCAL VOC dataset(2012)은 객체 탐지(object detection) 및 분할(segmentation) 태스크에서 일반적으로 사용됩니다. 11k개(11000개) 이상의 이미지를 통해 train 및 validation 데이터셋을 구성하고 10k(10000개)개의 이미지는 테스트 데이터셋으로 사용됩니다.
이미지 분할 대회(Segmentation challenge)는 mIoU(mean Intersection over Union)라는 평가 지표(metric)를 사용해 알고리즘을 평가합니다. IoU(Intersection over Union)는 예측된 오브젝트 위치의 연관성(relevance)을 평가하기 위해 객체 탐지(Object detection)에도 사용되는 평가 지표입니다. IoU는 정답 영역과 모델이 예측한 영역의 중첩된 영역(intersection)과 정답 영역+모델 예측 영역(Union)에 대한 비율로 정의됩니다. mIoU는 테스트 데이터셋의 모든 이미지에 대해 세그멘테이션된 객체들의 모든 IoU 평균값입니다.

▲ 이미지 분할(Image Segmentation)을 위한 2012 PASCAL VOC dataset의 예 (출처 : http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html)
PASCAL-Context 데이터셋
PASCAL-Context 데이터셋(2014)은 2010 PASCAL VOC 데이터셋의 확장 데이터셋입니다. 훈련(train)용으로 약 10k장, 검증(validation)용으로 10k 및 테스트용으로 10k장의 이미지가 포함되어 있습니다. 이 새로운 데이터셋의 특징은 전체 장면들에 대해 400개 이상의 분할된 범주(segmented categories)들을 제공한다는 것입니다. 사내의 라벨러 여섯 명이 3개월여에 걸쳐 이미지에 주석을 달았습니다. PASCAL-Context 대회의 공식 평가 지표는 mIoU입니다. 픽셀 정확도(pixel Accuracy)라는 다른 메트릭도 있지만 여기선 성능을 비교할 때 mIoU로만 비교합니다.
▲ PASCAL-Context 데이터셋의 예 (출처 : https://cs.stanford.edu/~roozbeh/pascal-context/)
Common Objects in COntext (COCO) 데이터셋
2017년과 2018년에 Image semantic segmentation을 주제로 두 개의 COCO 대회(‘Object detection’과 ‘stuff segmentation’)가 열렸습니다. ‘Object detection’대회는 개체를 80개의 카테고리로 분류하는 대회이고, ‘stuff segmentation’은 이미지를 큰 세그먼트 조각(하늘, 벽, 잔디 등)으로 나눈 데이터를 사용하며, 이 정보들은 거의 모든 시각적 정보를 포함하고 있습니다. 본 블로그 포스팅에서는 ‘Object detection’ 대회에서 나온 결과들만 언급할 것인데, 그 이유는 ‘stuff segmentation’대회는 인용된 논문 수가 많지 않기 때문입니다.
Object segmentation을 위한 COCO 데이터셋은 500k개가 넘는 객체 인스턴스(Object instance)로 세그먼트화된 200k장 이상의 이미지들로 구성됩니다. 여기에는 training, validation, 연구자들을 위한 test 데이터셋(test-dev) 및 대회를 위한 test 데이터셋(test-challenge)이 포함됩니다. 두 테스트 데이터셋의 주석(annotations)은 사용할 수 없도록 되어 있습니다. 이러한 데이터셋에는 80개의 카테고리가 포함되어 있으며 80개의 카테고리에 해당하는 개체만 세그먼트화되어 있습니다. 이 대회는 IoU(Intersection over Union)를 사용하는 객체 감지 대회와 동일한 평가 지표인 Average Precision (AP)과 Average Recall (AR)을 사용합니다.
IoU 및 AP 평가 지표에 대한 자세한 내용은 이전 블로그 게시물에서 확인할 수 있습니다. AP와 같이, Average Recall은 특정 범위의 중첩값을 가진 여러 IoU를 사용하여 계산됩니다. (Such as the AP, the Average Recall is computed using multiple IoU with a specific range of overlapping values.) 고정된 IoU의 경우 서로 대응하는 테스트/정답의 겹치는 영역은 유지됩니다. 그런 다음 탐지된 개체에 대한 Recall 평가 지표가 계산됩니다. (Recall = True Positive / (True Positive + False Negative)) 최종 AR(Average Recall) 평가 지표는 모든 IoU 범위값(IoU range values)에 대해 계산된 Recall의 평균입니다. 기본적으로 세그멘테이션 태스크에 대한 AP 및 AR 평가 지표는 semantic segmentiaton을 위해 직사각형이 아닌 형태, 즉 픽셀 단위로 IoU가 계산된다는 점을 제외하면 Object detection에서의 방식과 동일하게 계산됩니다.

▲ 객체 세분화(Object segmentation)를 위한 COCO 데이터셋의 예 (출처 : http://cocodataset.org/)
Cityscapes 데이터셋
Cityscapes 데이터셋은 2016년에 공개되었으며 50개 도시에 대해 세그먼트화된 도시 이미지들로 구성되어 있습니다. Train 및 validation을 위한 23.5k장의 이미지(정밀하고 거칠게 주석이 달린)들과 테스트를 위한 1.5k장의 이미지(정밀한 주석만 달린)들로 구성되어 있습니다. 이미지는 땅, 인간, 차량, 구조물, 객체, 자연물, 하늘, 텅 빈 부분 8개의 슈퍼 카테고리 내에서 29개의 클래스로 PASCAL-Context 데이터셋처럼 분할되어 있습니다. 꽤 복잡하기 때문에 semantic segmentation 모델을 평가하는 데 종종 사용되기도 합니다. 또한 자율 주행을 위한 실제 거리 이미지들과 상당히 유사성을 지니는 것으로도 유명합니다. Semantic segmentation 모델의 성능은 PASCAL 데이터셋처럼 mIoU 평가 지표를 사용하여 계산됩니다.

▲ Cityscapes 데이터셋의 예 (출처 : https://www.cityscapes-dataset.com/)
네트워크 소개
Fully Convolutional Network(FCN)
J. Long et al. (2015)은 이미지 세분화(Image segmentation) 문제를 위해 종단 간(end-to-end) 훈련을 수행하는 FCN(Fully Connectec Network)를 개발한 연구자들입니다.
FCN은 임의 크기의 이미지를 가져와 입력과 동일한 크기의 segmented image를 생성합니다. 저자들은 잘 알려진 네트워크 아키텍쳐(AlexNet, VGG16, GoogleLeNet)의 Fully connected Layers(FCs)를 합성곱 레이어(Convolution layers)로 대체함으로서 고정되지 않은 사이즈를 가진 인풋 이미지를 받을 수 있게 했습니다. 네트워크는 (레이어를 거칠수록) 크기가 작고 (정보의) 밀도가 높은 여러 feature map을 생성하므로 입력과 동일한 크기의 출력을 생성하기 위해선 업샘플링 과정이 필요합니다. 기본적으로 (업샘플링 과정은) stride가 1보다 낮은 합성곱 레이어들로 구성됩니다. 입력보다 큰 출력을 생성하기 때문에 일반적으로 이를 역 합성곱 연산(Deconvolution)이라고 합니다. 이러한 방법들을 통해 네트워크는 픽셀당 손실(pixel-wise loss)을 최소화하는 방향으로 학습됩니다. 또한 네트워크에 skip-connection 구조를 추가해 높은 레벨의 feature map representation을 네트워크 상단에 있는 보다 구체적이고 밀도가 높은 representation와 결합하도록 했습니다.
저자들은 2012 ImageNet 데이터셋으로 pretrain된 모델을 사용하여 2012 PASCAL VOC segmentation 대회에서 62.2%의 mIoU 점수를 얻었습니다. 그에 비해 2012 PASCAL VOC object detection 대회에서는 Faster R-CNN이라는 모델이 78.8% mIoU 점수를 얻었습니다. 두 대회의 결과(다른 모델, 다른 데이터셋 및 다른 문제)를 직접 비교할 수 없긴 하지만, semantic segmentation 태스크는 object detection 태스크에 비해 훨씬 어려운 문제인 것 같습니다.
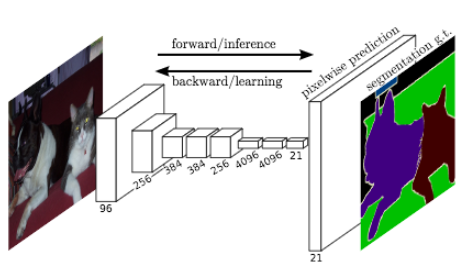
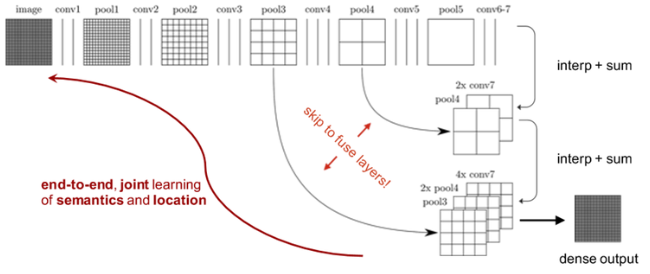
▲ FCN의 아키텍쳐. (아래의 Skip-connection 그림은 역자가 추가)(출처 : J. Long et al. (2015))
ParseNet
W. Liu et al. (2015)은 J. Long et al. (2015)의 FCN 모델을 개선한 논문을 발표했습니다. 저자들에 따르면, FCN 모델은 생성된 feature maps를 specializing하여 깊은 레이어에서 이미지의 글로벌 컨텍스트를 잃게 됩니다. ParseNet은 모든 픽셀의 값을 동시에 예측하는 종단 간(end-to-end) 합성곱 네트워크로서 전역 정보를 유지하기 위해 특정 영역을 입력으로 사용하지 않습니다. 저자들은 feature maps를 입력으로 사용하는 모듈을 사용했습니다. 첫 번째 단계에서 모델을 통해 풀링 레이어를 통해 단일 전역 피쳐 벡터(single global feature vector)로 축소된 feature map을 생성합니다. 이 컨텍스트 벡터는 L2 Euclidean Norm을 사용하여 정규화(Normalization)되며, 역 풀링(Unpool, the output of unpool is an expanded version of the input)을 통해 초기(Initial) feature map과 동일한 크기의 새 feature map을 생성합니다. 두 번째 단계에서는 L2 Euclidean Norm을 사용해 전체 초기 feature map을 정규화(Normalization)합니다. 마지막 단계에서는 앞선 두 단계에서 생성된 feature map을 연결(concatenate)합니다. 정규화는 연결된 feature maps들의 값을 스케일링하는 데 도움이 되며, 성능을 향상시켜 줍니다. 기본적으로 ParseNet은 FCN의 합성곱 레이어들을 앞서 설명한 모듈로 대체한 것입니다. ParseNet은 PASCAL-Context 대회에서 40.4%의 mIoU 점수를, 2012 PASCAL VOC segmentation 대회에서는 69.8%의 mIoU 점수를 획득했습니다.
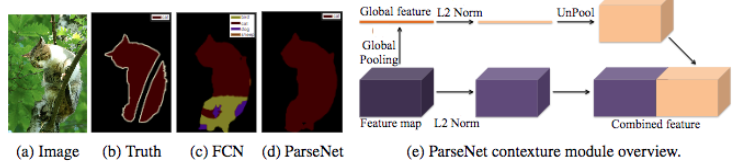
▲ FCN과 ParseNet의 segmentation 결과 비교(좌측) 및 ParseNet module의 아키텍쳐. (출처 : W. Liu et al. (2015))
Convolutional and Deconvolutional Networks
H. Noh et al. (2015)는 두 개의 연결된 파트로 구성된 종단 간(end-to-end) 모델을 공개했습니다. 첫 번째 파트는 VGG16 아키텍쳐의 합성곱 네트워크입니다. 이 파트에서는 object detection 모델에 의해 생성된 인스턴스 후보(Instance proposal)를 경계 상자(bounding box)와 같은 형태로 입력받습니다. 이 후보들은 합성곱 신경망에 의해 처리 및 변형되어 특징 벡터(feature vector)를 생성합니다. 두 번째 파트는 ‘역 합성곱 네트워크(deconvolution network)’라고 부르며, 첫 번째 파트에서 생성한 feature vector를 입력으로 받아 각 클래스에 속하는 픽셀 단위 확률 맵(pixel-wise probability map)을 생성합니다. 역 합성곱 네트워크는 map 안에 존재하는 위치 정보를 보존하기 위해 역 풀링(unpooling)을 사용하여 map에서 최대로 활성화된 부분(maximum activations)을 가리킵니다. 두 번째 파트에 해당하는 네트워크는 또한 단일 입력을 여러 개의 feature map으로 연결하는 역 합성곱 연산도 사용합니다. 역 합성곱 연산은 정보의 밀도를 유지하면서 feature map을 (여러 개로) 확장합니다.
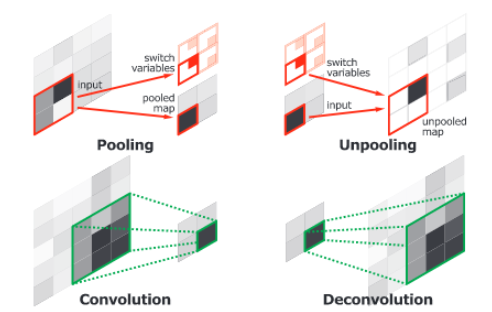
▲ 합성곱 네트워크의 레이어(Pooling과 convolution)와 역 합성곱 네트워크의 레이어(unpooling과 deconvolution)를 비교한 그림. (출처 : H. Noh et al. (2015))
저자들은 역 합성곱 연산을 통해 뽑은 feature map들에 대해 분석하였으며, 낮은 레벨의 feature map은 후보들에 대해 분류 작업을 수행하는 데 도움이 된다고 주장합니다. 마지막으로, 이미지 내의 모든 후보들에 대해 전체 네트워크로 연산을 수행한 후 연산의 결과로 나온 map들을 연결(concatenate)하여 전체 분할 이미지(fully segmented image)를 얻습니다. 이 네트워크는 2012 PASCAL VOC segmentation 대회에서 72.5%의 mIoU점수를 얻었습니다.
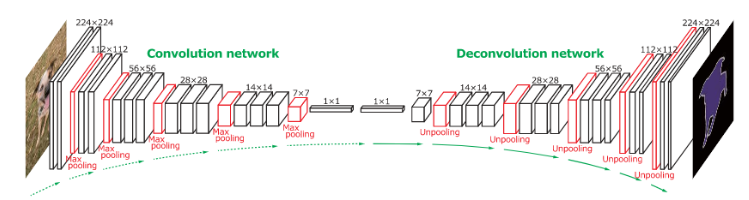
▲ 전체 네트워크 아키텍쳐. 합성곱 네트워크 부분은 VGG16 아키텍쳐를 기반으로 합니다. 역 합성곱 네트워크 부분은 역 풀링(unpooling) 및 역 합성곱(deconvolution) 레이어를 사용합니다. (출처 : H. Noh et al. (2015))
U-Net
O. Ronneberger et al. (2015)은 J. Long et al. (2015)의 FCN을 확장해 생물학 현미경을 위한 모델을 제안했습니다. 저자들은 (주어진 이미지에서) feature를 뽑아내는 역할을 수행하는 추출(Contraction) 파트와 이미지에 존재하는 패턴을 공간적으로 지역화(spatially localize)하는 확장(Expansion) 파트 두 개의 부분으로 구성되어 있는 U-Net이라는 네트워크를 만들었습니다. 추출(Contraction) 파트(Downsampling으로도 부름)는 FCN 네트워크와 비슷한 구조를 갖고 있으며, 3x3 사이즈의 합성곱 연산을 통해 feature를 추출합니다. 확장(Expansion) 파트(Upsampling으로도 부름)는 역 합성곱(deconvolution, 또는 up-convolution으로도 부름)연산을 사용해 feature map의 개수를 줄이면서 높이와 너비를 늘려 나갑니다. 네트워크의 Downsampling 부분에서 잘라낸 feature map은 (이미지에 존재하는) 패턴 정보가 손실되지 않도록 Upsampling부분으로 복사됩니다. 마지막으로, 1*1 합성곱 연산은 feature map을 처리해 segmentation map을 생성하고 입력 이미지의 각 픽셀을 분류합니다. U-Net이 발표된 이후, U-Net은 최근의 연구들(FPN, PSPNet, DeepLabV3 등)에서 광범위하게 사용되었습니다. 완전히 연결된 레이어(Fully-connected layer)들을 사용하지 않는다는 점에 주목할 필요가 있습니다. 결과적으로 U-Net은 모델의 매개 변수(parameter)의 개수가 줄어들고 적절한 데이터 증강(Data augmentation) 기법을 적용하여 적게 레이블이 지정된 데이터셋으로도 훈련할 수 있습니다. 예를 들어, U-Net의 저자는 실험 중 train을 위해 공개된 데이터셋 중 30장의 이미지만을 사용했습니다.
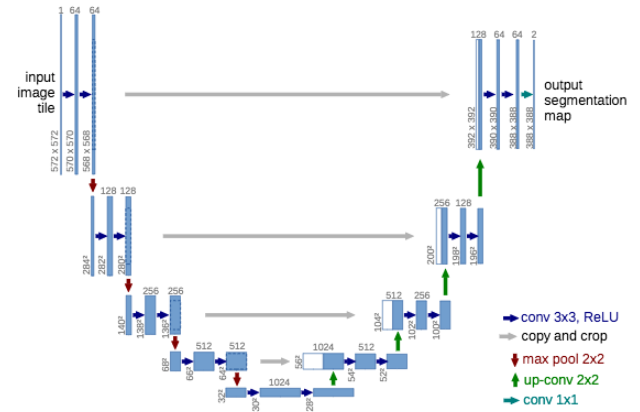
▲ 인풋 이미지 사이즈와 함께 도식화한 U-Net 아키텍쳐.(출처 : O. Ronneberger et al. (2015))
(이하 번역중입니다.)