(Event/Seminar후기) T.TOC 최신논문공유회 - Variational prototyping encoder one shot learning with prototypical images
in Devlog / Paperreview / Event&Seminar on Ml, Dl, Meta learning, Few shot learning, Vae
본 글은 2019년 7월 17일 SKT T.TOC 주최 최신논문공유회에 참석해 김준식 연사님의 세미나를 받아적은 포스트입니다. 저자 공식 의견과 맞지 않는 내용이 포함되어 있을 수 있으니 원본 논문을 확인해 보시기 바랍니다.
본 논문은 CVPR 2019 Oral Session에서 발표된 논문입니다. 로고나 퍼블릭 사인(Public sign)같이 Prototype을 기반으로 한 심볼(Symbol)들을 인식하는 태스크에 대해 다루고 있습니다. 나라 또는 회사마다 심볼 디자인이 다른 경우 그러한 모든 경우들에 대한 데이터셋을 구성하기란 쉬운 일이 아닙니다. 따라서 본 논문과 같은 Few-shot learning 기반의 방법을 제안하였습니다. 개인적으로 아카이빙을 위해 만든 포스트이므로 어투가 다소 딱딱한 점 너른 양해 부탁드리겠습니다.
목적
기존 데이터셋에서는 데이터셋의 스케일이 크더라도 각 클래스별 분포의 불균형으로 인해 모델을 완벽하게 학습시키는 데에 어려움이 존재
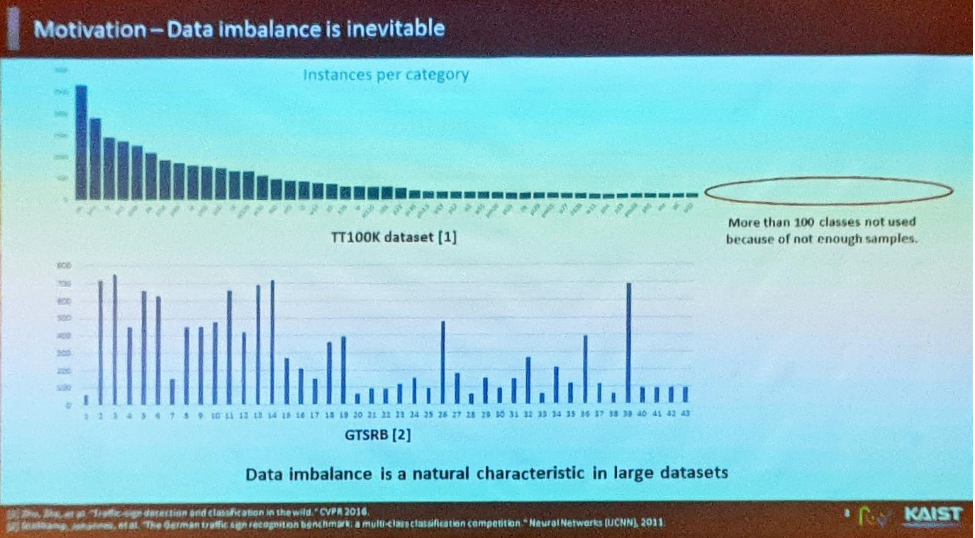
- 특정 클래스에 데이터들이 몰려 있고 나머지 부분은 few-shot이라는 한계 존재. TT100K 데이터셋의 경우에도 다섯개 도시 인근에서 10만개의 데이터를 캡쳐했음에도 평가를 하기 어려운 클래스들이 존재하는 제약사향이 잔존.
- 따라서 상기 문제를 해결하고자 하며, 이 문제들이 해결되면 Brand Logo 인식, Public sign 인식을 통한 환경 이해(Understand an environment), Traffic sign 이해를 통한 교통환경 이해(Understand traffic for autonomous vehicle)문제와 같은 다양한 태스크에 적용 가능.
Few Shot Learning
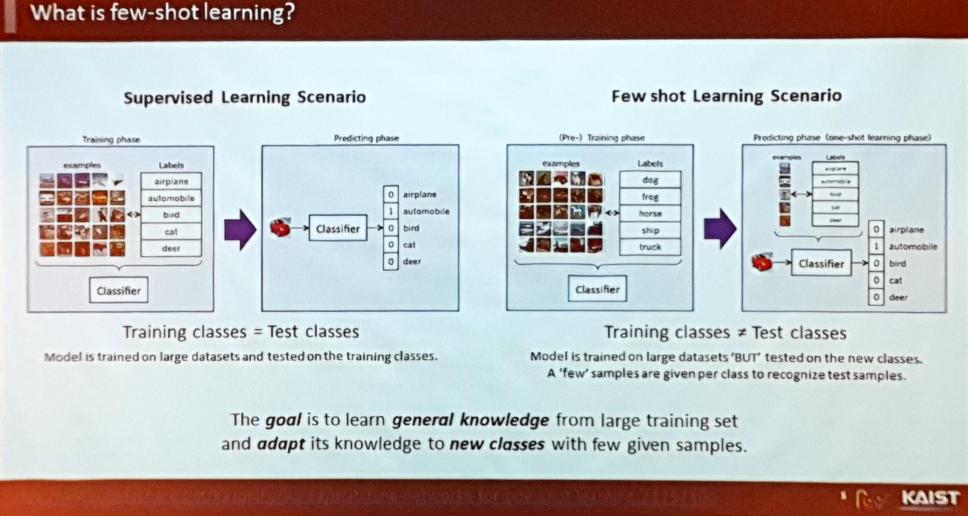
- 훈련 과정에서는 고정된 클래스를 사용하지 않고 랜덤 클래스 샘플링 후 서로 다른 클래스라는 가정을 두어 학습.
- 훈련 과정의 핵심은 Large Dataset Training 과정에서 일반화(Generalization)를 잘 수행한 후 소량의 Few-shot 데이터에서도 Knowledge가 얼마나 빠르게 잘 적용되는지 확인하는 것.
Few Shot Learning의 과정
- 전형적인 퓨샷 러닝의 과정 :
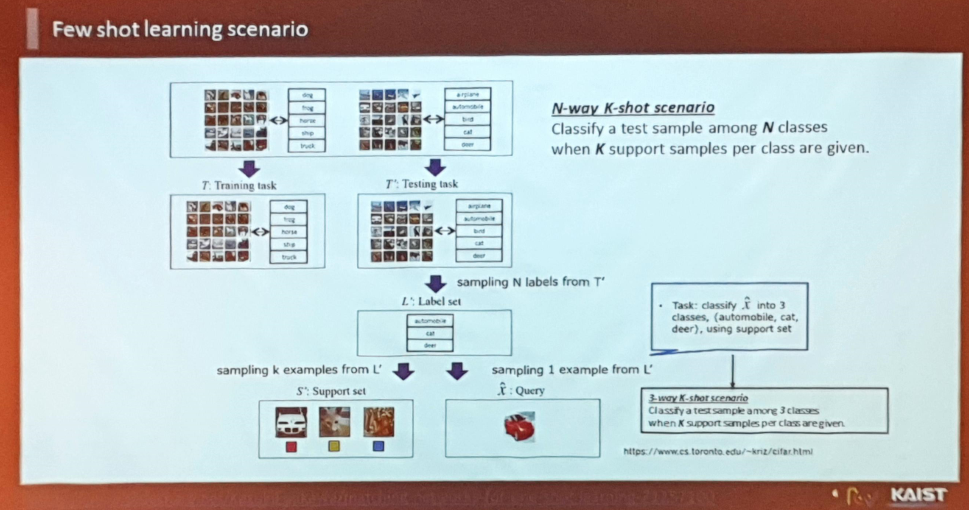
- 그러나 심볼 분류 부문에서의 Few shot 논문은 찾아보기 힘듦.
논문 개요
- Prototypical이란 : Prototype이 존재하는 객체(Object)를 의미.
베이스라인 선정 및 테스트 :
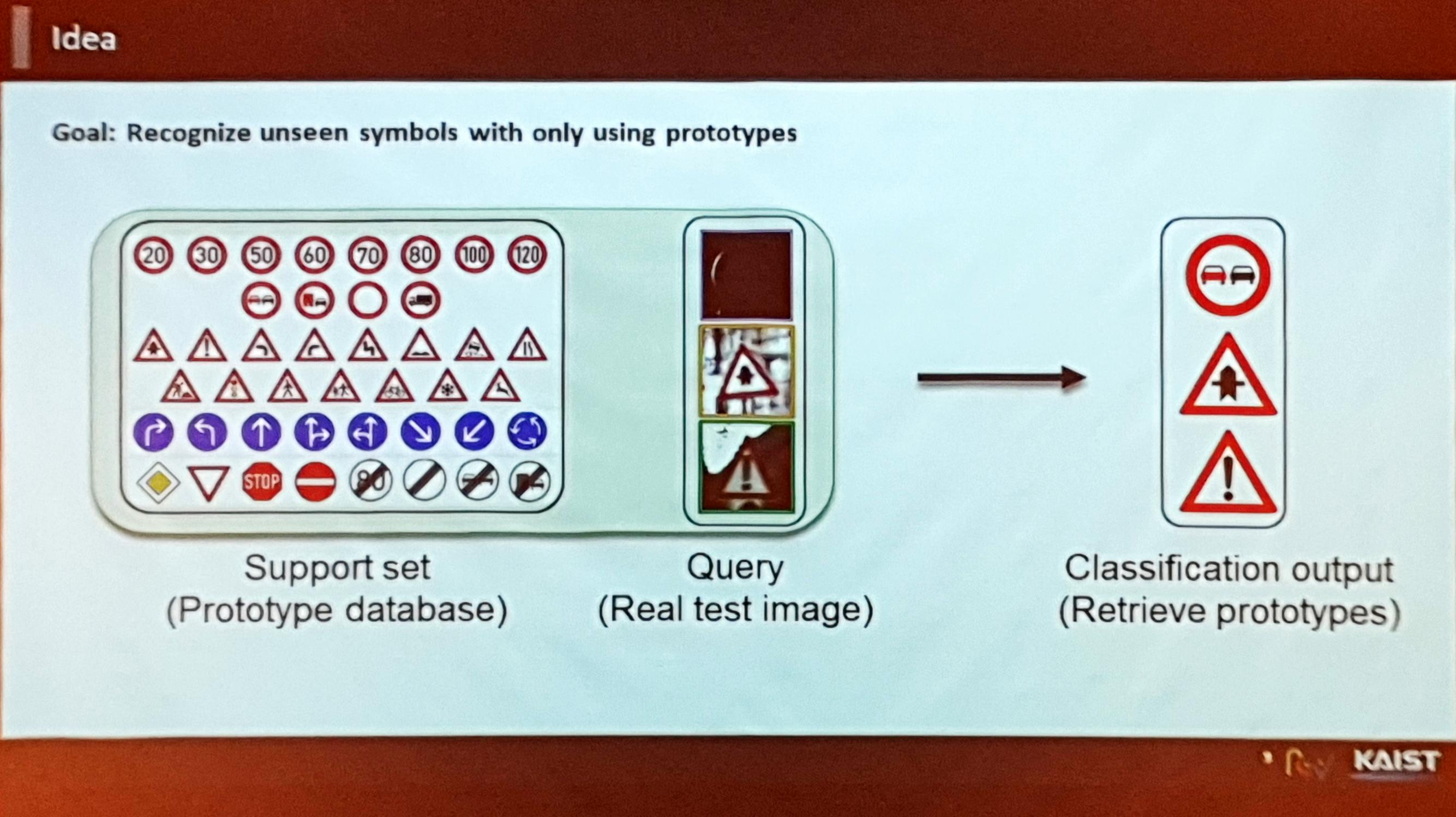
- 각 클래스마다 프로토타입(원형, 사각형, 삼각형 등)이 한개씩 정의되어 있으므로 One-shot learning으로 볼 수도 있음.
- 임베딩 학습을 잘 하게 된다면, 더 나아가 (프로토타입에 대해) 일반화가 잘 된다면 한번도 보지 않은 새로운 클래스에 대해서도 매핑이 잘 될 것임.
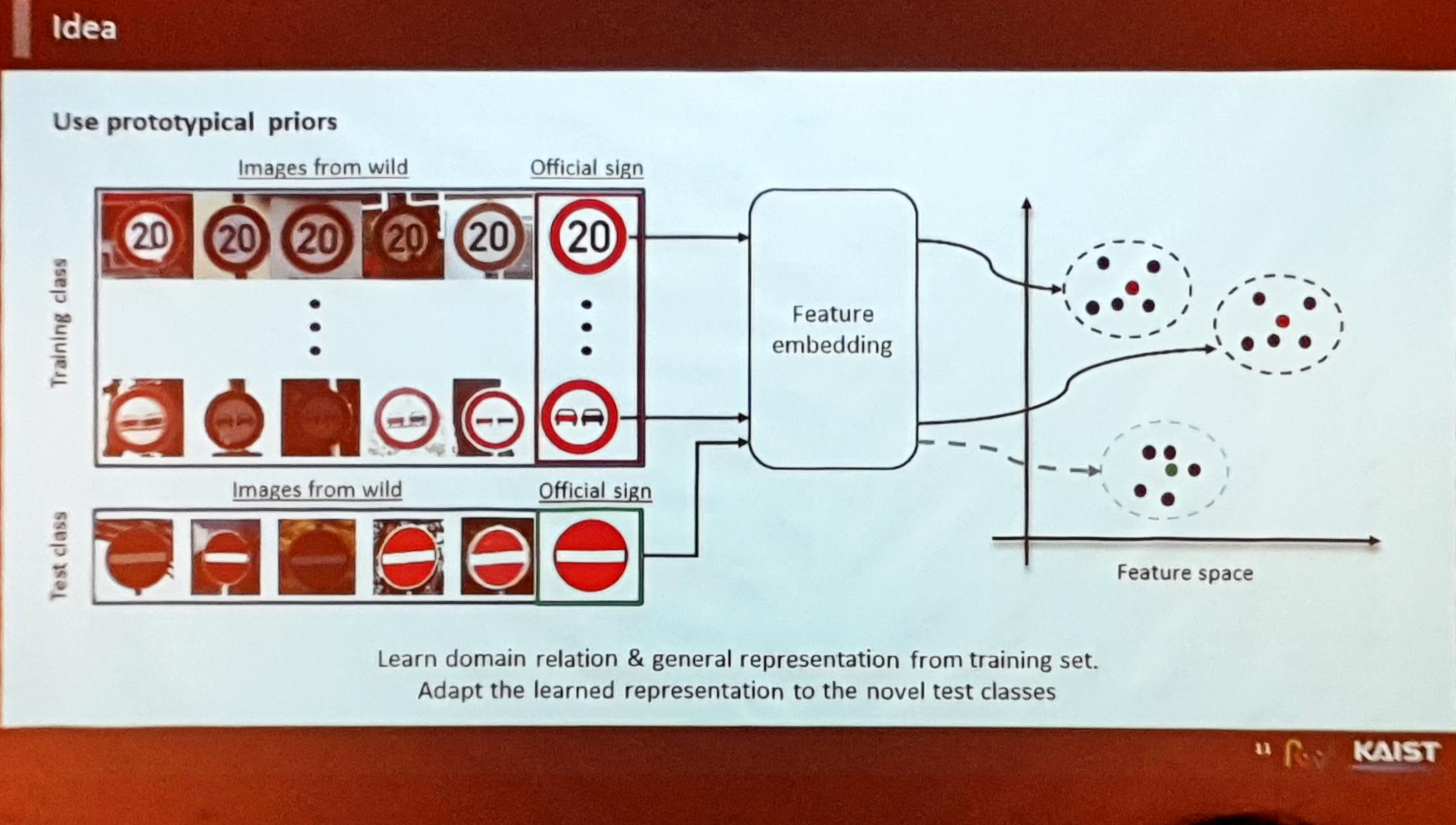
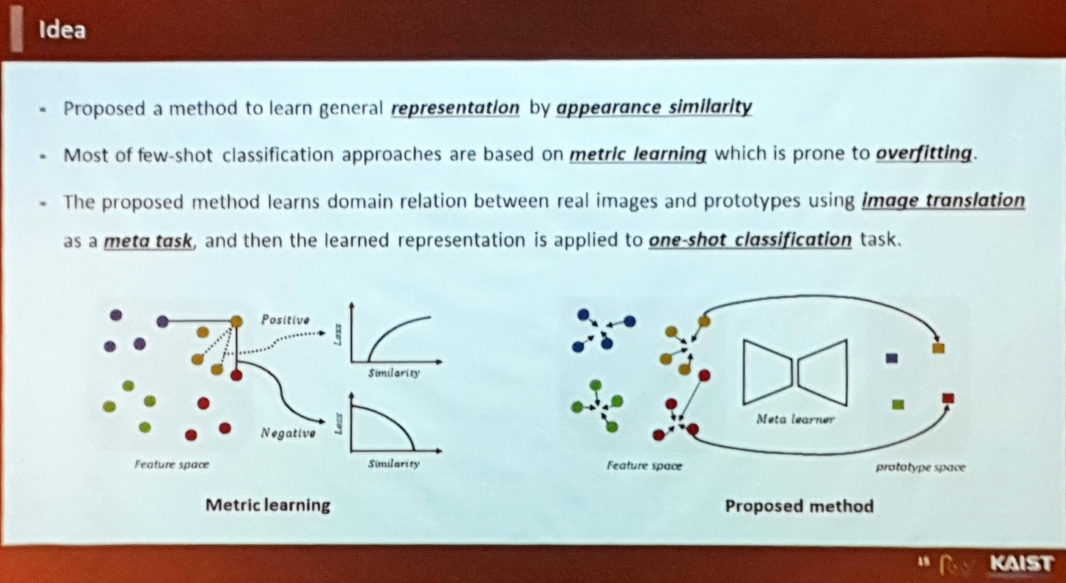
- 작년까지는 Metric Learning 위주의 연구가 주를 이루었음
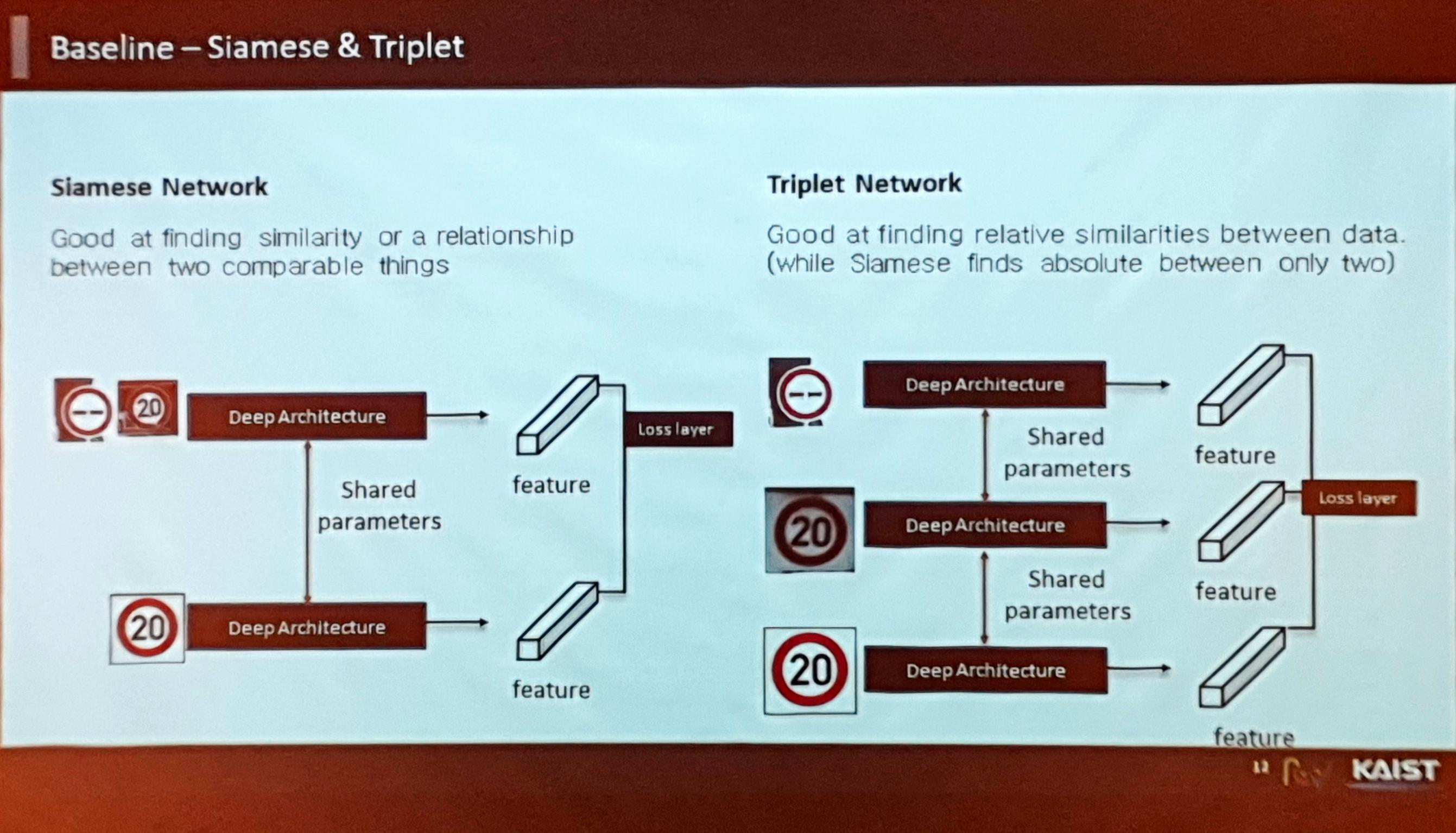
- Metric Learning의 종류 중 하나인 Siamese Network같은 경우 두 개의 descriptor로부터 feature를 뽑아 얼마나 다른지, 혹은 같은지 여부를 비교하는 태스크 수행
- 마찬가지로 Metric Learning의 종류 중 하나인 Triplet Network는 Positive, Negative sample을 뽑아 원본과 비교 수행
- 본 논문 저자들은 Siamese와 Triplet 두 개의 네트워크를 베이스라인으로 삼아 테스트를 진행 - Support set에는 프로토타입들이 있으므로 feature space에 미리 매핑해두고 test 샘플이 들어올 때마다 거리(metric)를 재어 metric learning의 컨셉대로 진행.
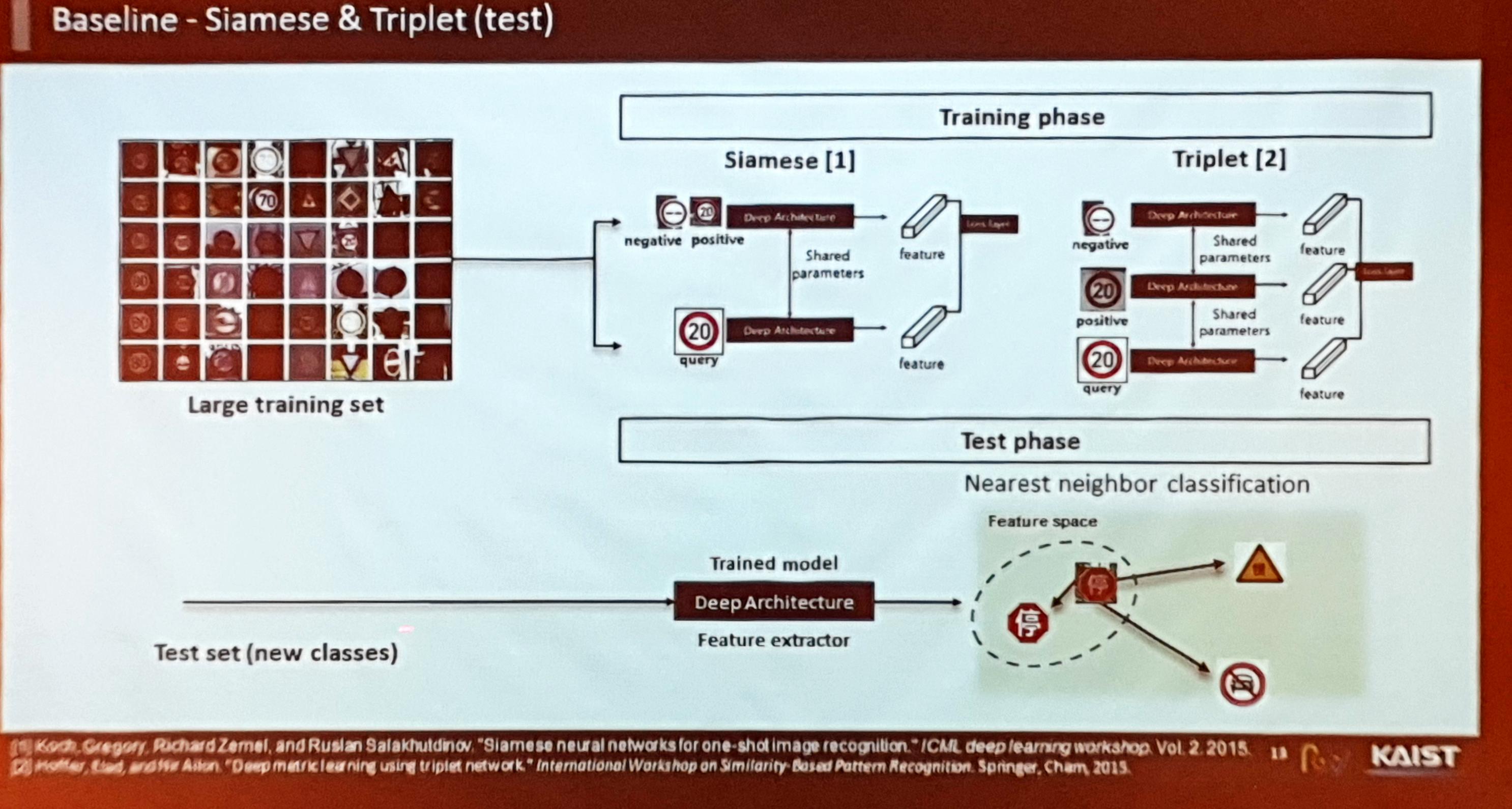
그러나 Metric Learning 기반의 아이디어들은 Overfitting으로 인해 성능이 좋지 않았음. 따라서 규제를 어떻게 잘 해줄 것인가가 중요하게 작용.
논문의 아이디어
- Metric Learning 방법론은 같은 클래스 라벨끼리는 metric을 가깝게, 그 반대의 경우는 멀어지게 하도록 loss를 정의함.
- 그러나 클래스가 ‘같은지’ 또는 ‘다른지’의 바이너리 정보만으로 학습하기 때문에 유사성을 학습하기 어렵다.
따라서 본 논문 저자들은 Image to Image Translation 기법을 기반으로 feature space 자체를 잘 학습하고자 하였음.
VAE(Variational Auto-Encoder)와 AE(Auto-Encoder)의 다른 점 :
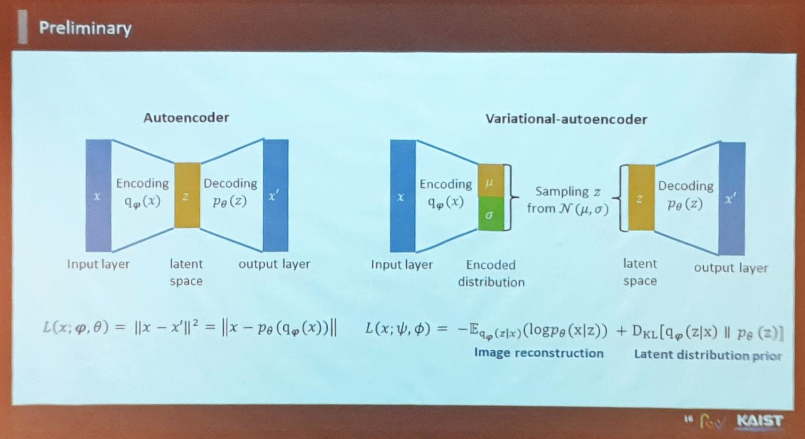
- AE는 Determistic하게 이미지와 feature에 대해 정의하지만, VAE는 feature의 분산을 예측한다는 점에서 차이가 있음. VAE는 학습한 분산을 기반으로 하여 원본 데이터를 유추하게 된다.
- VAE에는 sampling이 포함되어 있으며, 잠재공간(Latent Space)을 규제하는 부분이 들어감.
- VAE 학습을 통해 벡터 공간에 임베딩된 이미지들은 사람이 보기에도 비슷해 보인다. 또한 본 연구에서는 Image to Image Translation 아이디어를 적용하기 위해 VAE를 적용.
- VAE를 사용할 경우 many-to-one 학습이므로 클러스터링 효과도 있음.
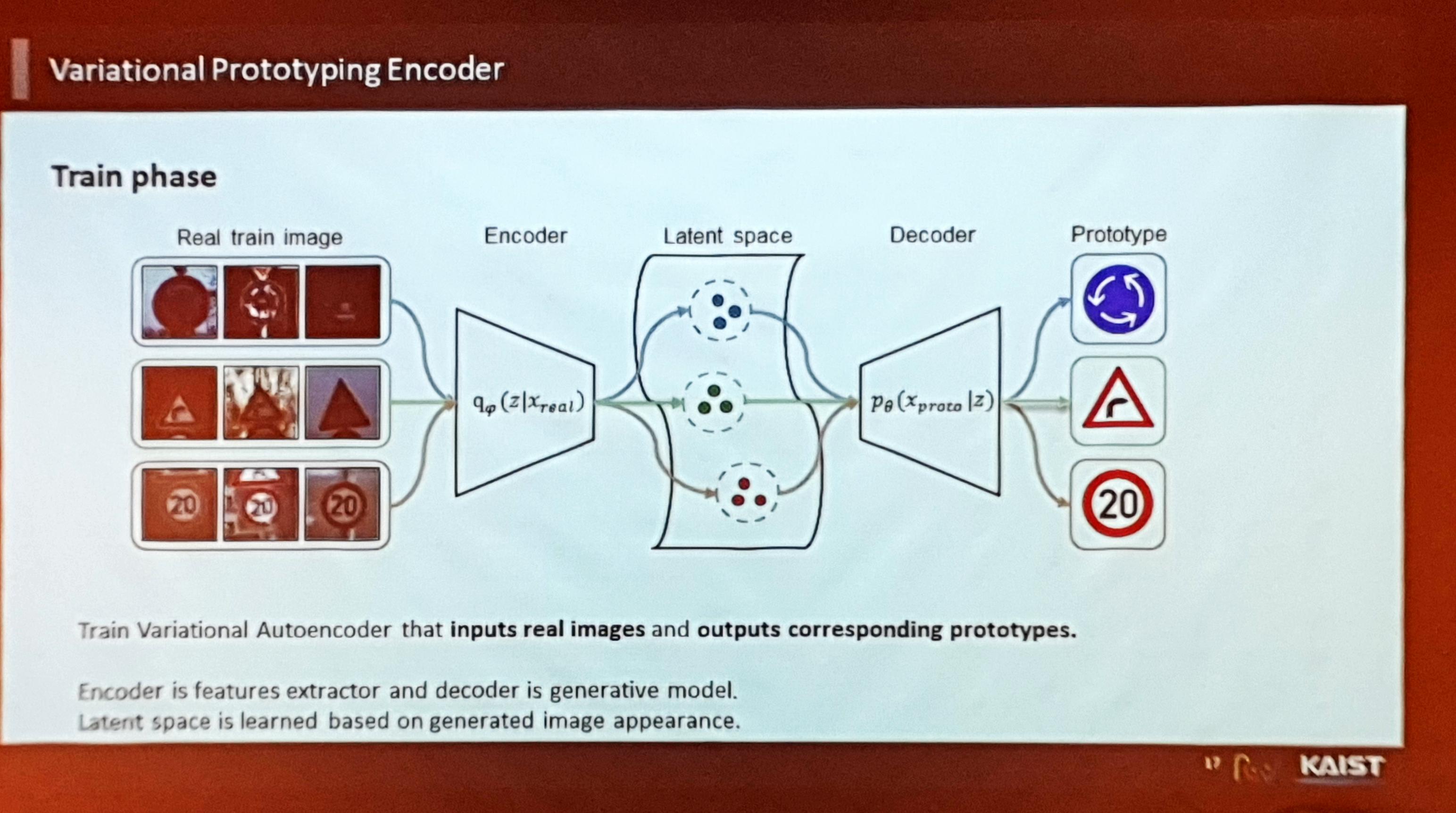
VPN(Variational Prototypical Encoder)
- 저자들은 VAE를 Prototype에 대해 정의한 VPN(Varational Prototyping Encoder) 네트워크를 제안. Loss는 VAE와 비슷하게 구성
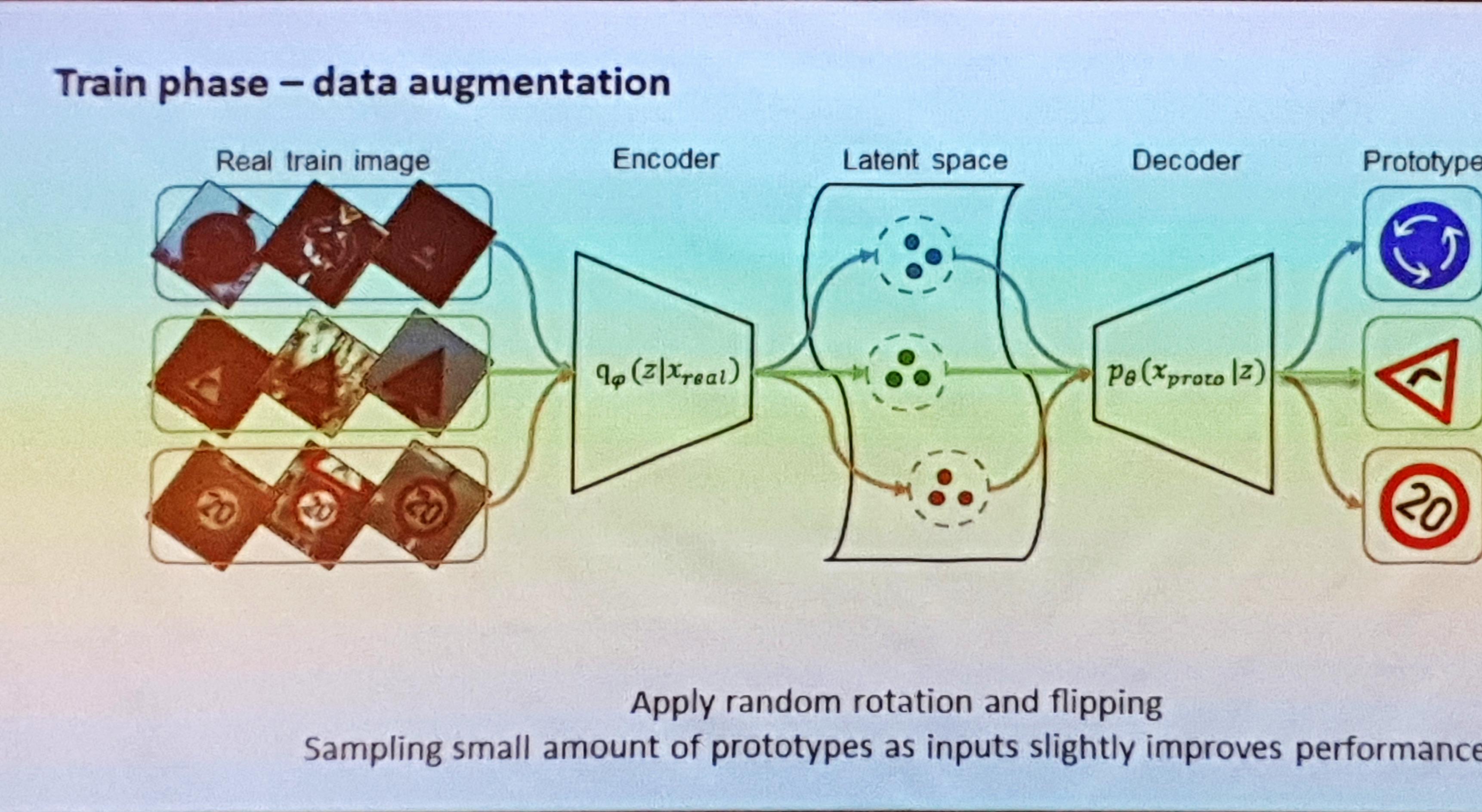
- Train Phase의 DB Augmentation은 다음과 같이 수행
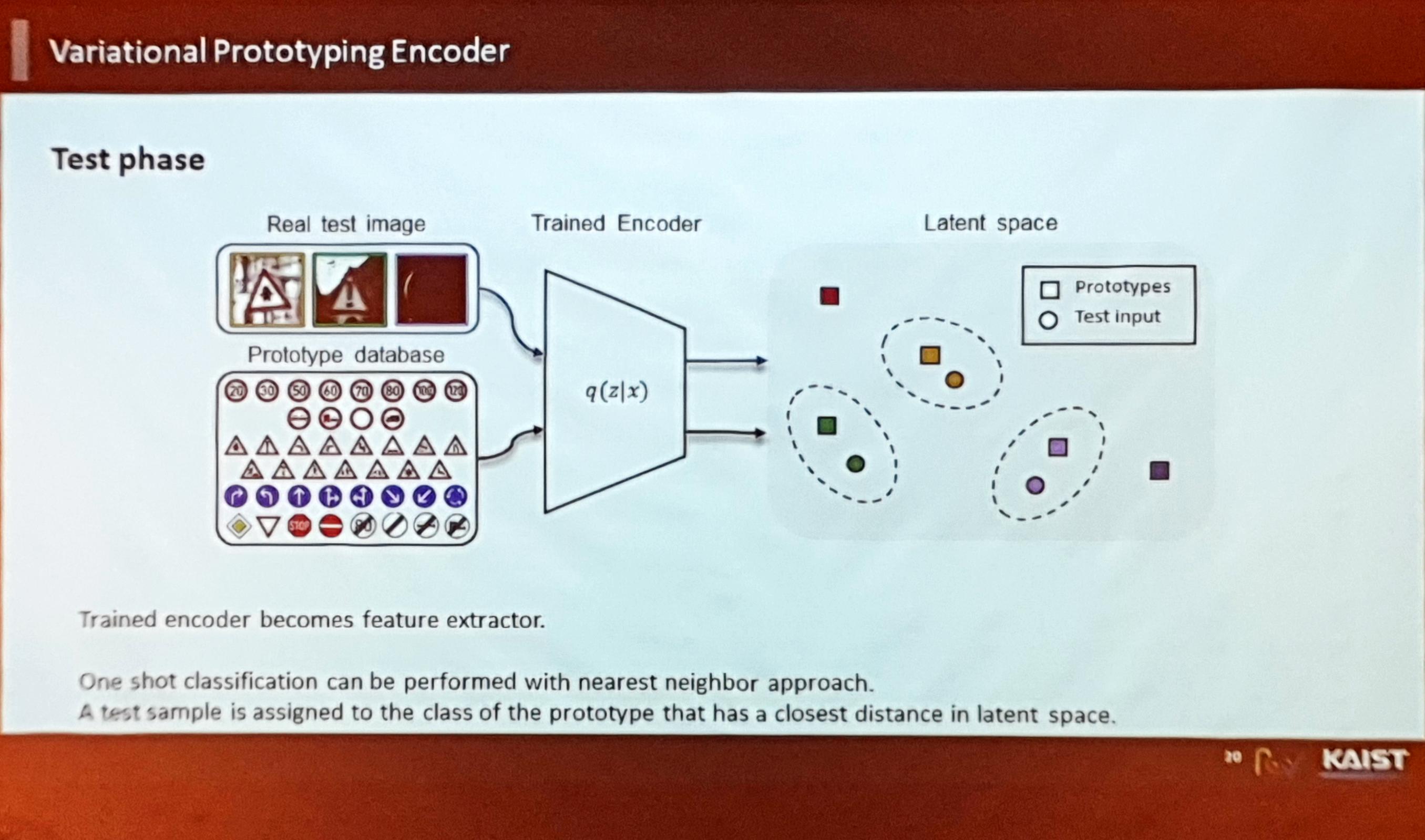
- Test Phase의 DB Augmentation은 다음과 같이 수행
실험(Experiments)

- Train 데이터 생김새

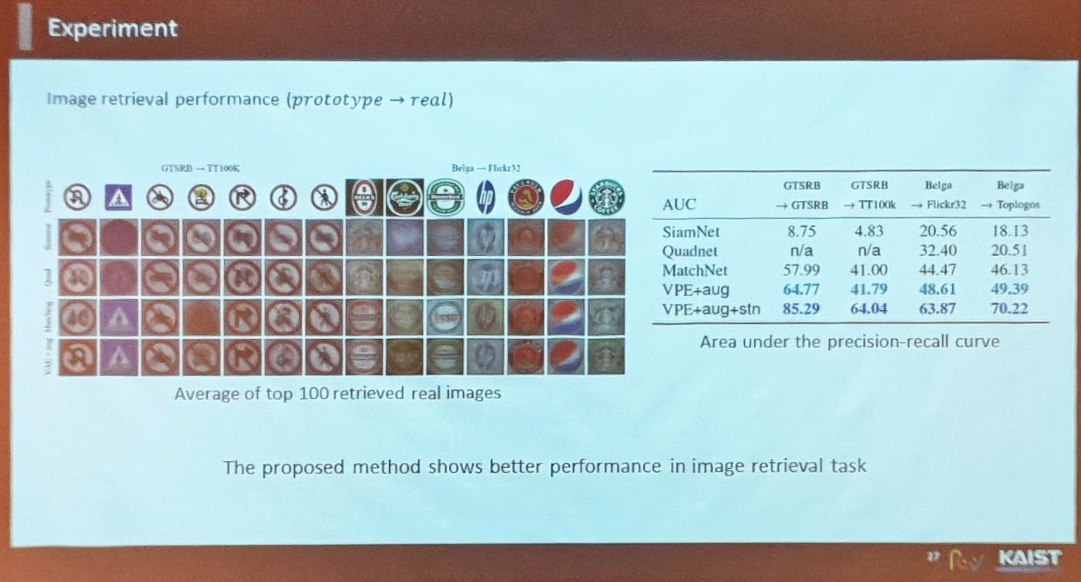
- (Metric Learning에서) 로고 데이터셋이 특히 어렵고 학습 결과가 좋지 않았으나 저자들이 제안한 VPE 네트워크를 통해 학습하면 더 나은 결과를 보임
- DB Augmentation을 수행했을 때와 수행하지 않았을 때의 차이가 큼.
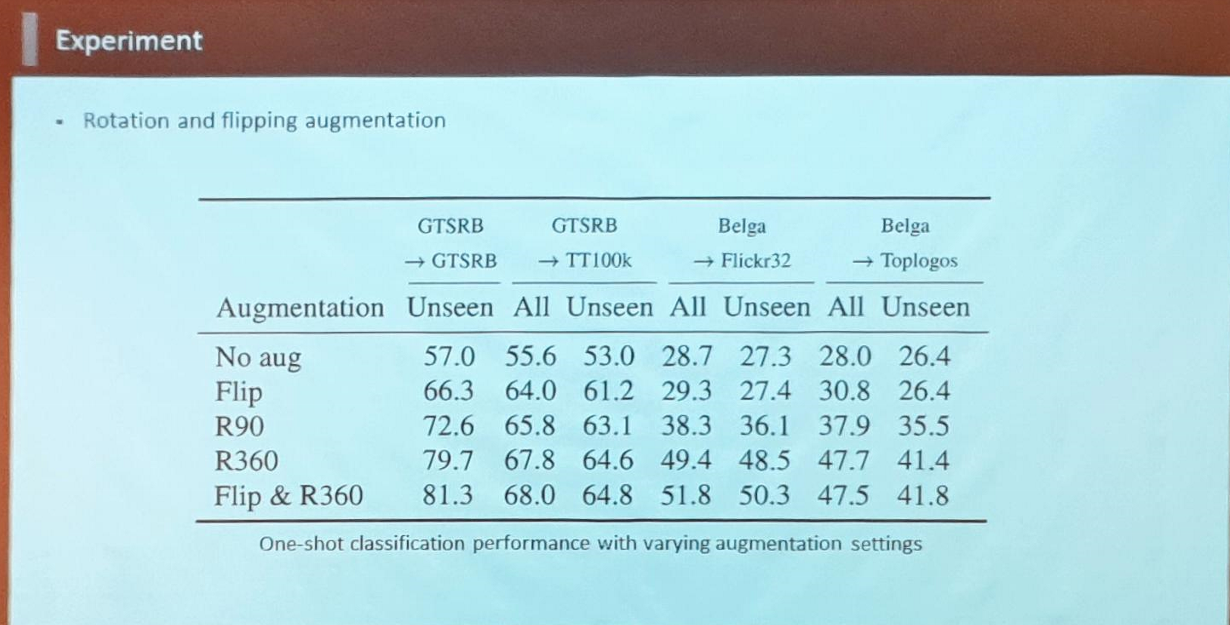
- STN(Spatial Transformation Network) 네트워크는 Traffic Sign Classification의 성능 향상에 도움이 됨.
- Image Retrieval에서의 성능 비교 (프로토타입들을 쿼리로 넣고 100개 정도의 결과를 average)
- Embeded Features를 t-SNE로 시각해본 결과 :
