LabelBox annotation 데이터 정제해 세그먼테이션 정답 이미지로 저장하기

이번 글에서는 Labelbox로 annotation한 이미지를 세그먼테이션 태스크에 활용할 수 있도록 Segment map으로 변환하는 과정에 대해 다뤄 봅니다.
이번 글에서는 Labelbox로 annotation한 이미지를 세그먼테이션 태스크에 활용할 수 있도록 Segment map으로 변환하는 과정에 대해 다뤄 봅니다. LabelBox는 Object Detection, Segmentation, Classification 태스크의 라벨을 만들 수 있는 웹 기반 툴로, 개인 연구자는 최대 5명을 협업자로 추가해 2500장 이미지의 라벨링 작업을 무료로 수행할 수 있습니다. 그 이상의 작업은 시간당 6달러를 지불하거나 따로 견적을 내어야 한다네요.
저는 Living Webtoon 프로젝트를 위해 TWDNE 데이터셋 중 560여 장을 추려 아래와 같이 eye, nose, mouth, eyebrow 네 클래스에 대해 annotation을 수행했습니다.

하지만 어노테이션을 끝낸 후 다운로드를 받는 과정에서 네 개의 클래스가 모두 합쳐진 이미지를 제공해 주지는 않습니다. 쓸만한 데이터는 각 이미지의 각 클래스별 폴리곤 버텍스 위치와 마스크 이미지 정도이고, LabelBox측에서 PASCAL VOC나 COCO스타일로 segmentation map을 만들어주는 코드를 제공하지만 라벨 컬러나 팔레트를 본인이 원하는 대로 변경하려면 마스크 이미지들을 받아 따로 수정할 필요가 있습니다.
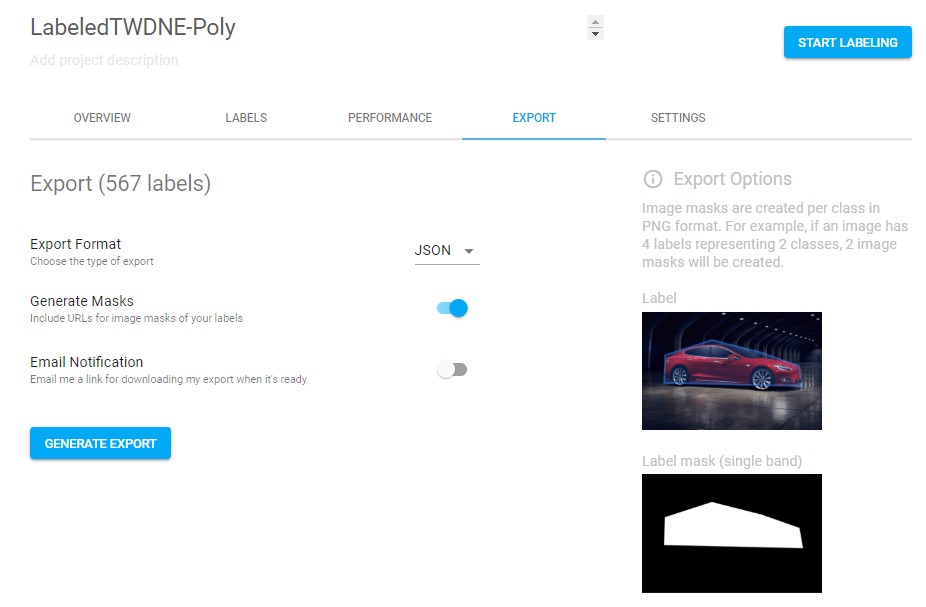
라벨링을 어느 정도 끝내고 Export를 하게 되면 위와 같이 mask를 포함해 .json 또는 .csv 포맷으로 annotation 데이터를 다운로드받을 수 있습니다.
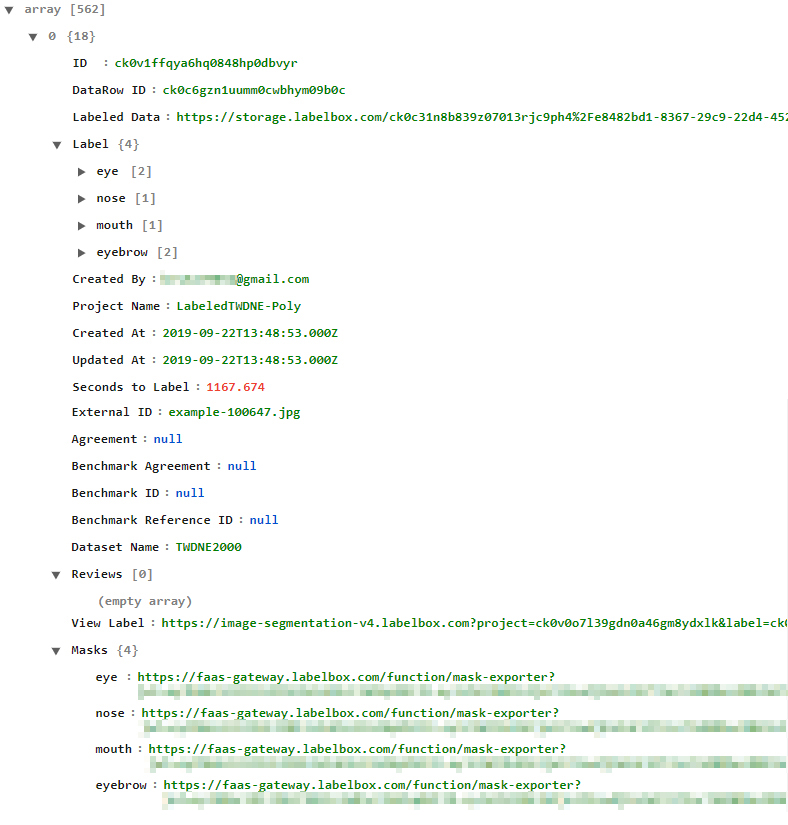
다운로드받은 json파일은 위와 같은 구조를 갖고 있습니다. Label은 segment 정보를 폴리곤으로 담고 있는 부분이고, 그 아래로 만든 사람과 프로젝트 이름, 생성 및 업데이트 날짜와 같은 부가 메타 정보가 기술되어 있습니다. 라벨링에 소요된 시간까지도 알 수 있네요. 우선 저희에게 제일 필요한 데이터는 라벨링된 이미지이기 때문에 Masks 항목의 링크를 통해 이미지를 확인해 보겠습니다.
위 이미지의 (c)처럼 깔끔하게 정돈된 이미지가 나와 주었으면 좋으련만, LabelBox에서는 (b)와 같이 클래스 단위로 바이너리 이미지를 제공해 주고 있습니다. 세그먼테이션 모델에 따라 학습 방식이 미묘하게 다를 수 있지만 보통 원본 이미지인 (a)를 입력으로 받아 형형색색의 클래스로 구분한 후 (c) 이미지를 정답 삼아 loss를 구하기 때문에 (b)와 같은 바이너리 이미지는 학습을 위한 정답 이미지로 넣어줄 수 없습니다. 지금부터 저 .json파일로부터 바이너리 이미지를 다운로드받은 후 색깔을 입혀 한 장의 segment map으로 만들어 보겠습니다.
JSON파일 뜯어보기
위의 JSON 트리 구조로 간략히 보여 드렸지만, 좀 더 자세히 JSON파일을 들여다 보겠습니다. 우선 working directory를 설정해 주겠습니다.
import os, glob
parent_dir = os.path.abspath(os.getcwd() + "/../")
dataset_img_savepath = os.path.join(os.path.abspath(os.getcwd() + "/../../../"), 'AnimFaceSeg_poly/animface/')
dataset_cat_savepath = os.path.join(os.path.abspath(os.getcwd() + "/../../../"), 'AnimFaceSeg_poly/category/')
dataset_txt_savepath = os.path.join(os.path.abspath(os.getcwd() + "/../../../"), 'AnimFaceSeg_poly/filelist/')
print(parent_dir)
print(dataset_img_savepath)
print(os.listdir(parent_dir))
C:\Users\MGL\AnimPortrait\AnimFaceSegmentaiton_pytorch
C:\Users\MGL\AnimFaceSeg_poly/animface/
['1.jpg', '2.jpg', '2_1.jpg', '3.jpg', '4.png', '5.jpg', '6.jpg', 'custom_transforms.py', 'dataLoader.py', 'decodeSegmap.py', 'export-2019-10-07T03_57_27.446Z.json', 'main.py', 'modeling', 'mypath.py', 'run', 'utils', '_target.png']
디렉토리 내의 파일들 중 json파일만 찾아 보겠습니다.
# .json파일만 조회
file_list = os.listdir(parent_dir)
file_list_json = [file for file in file_list if file.endswith(".json")]
print ("file_list_json : {}".format(file_list_json))
file_list_json : ['export-2019-10-07T03_57_27.446Z.json']
json 파일을 로딩한 후 첫 번째 인덱스만 출력해 보면 어떤 요소들을 포함하고 있는지 대충 파악할 수 있습니다.
import json
jsonpath = os.path.join(parent_dir, file_list_json[0])
with open(jsonpath) as json_file:
json_data = json.load(json_file)
json_data[0]
{'ID': 'ck0v1ffqya6hq0848hp0dbvyr',
'DataRow ID': 'ck0c6gzn1uumm0cwbhym09b0c',
'Labeled Data': 'https://storage.labelbox.com/ck0c31n8b',
'Label': {'eye': [{'geometry': [{'x': 299, 'y': 513},
(...)]},
{'geometry': [{'x': 589, 'y': 593},
(...)]}],
'nose': [{'geometry': [{'x': 532, 'y': 649},
(...)]}],
'mouth': [{'geometry': [{'x': 389, 'y': 775},
(...)]}],
'eyebrow': [{'geometry': [{'x': 309, 'y': 451},
(...)]},
{'geometry': [{'x': 624, 'y': 505},
(...)]}]},
'Created By': '________@gmail.com',
'Project Name': 'LabeledTWDNE-Poly',
'Created At': '2019-09-22T13:48:53.000Z',
'Updated At': '2019-09-22T13:48:53.000Z',
'Seconds to Label': 1167.674,
'External ID': 'example-100647.jpg',
'Agreement': None,
'Benchmark Agreement': None,
'Benchmark ID': None,
'Benchmark Reference ID': None,
'Dataset Name': 'TWDNE2000',
'Reviews': [],
'View Label': 'https://image-segmentation-v4.labelbox.com?',
'Masks': {'eye': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'nose': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'mouth': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'eyebrow': 'https://faas-gateway.labelbox.com/function/mask-exporter?'}}
Labeled Data 키는 원본 이미지입니다. 이름이 왜 Labeled Data인지는 모르겠지만 해당 이미지를 확인해 보면 원본 이미지가 나오는 것을 확인할 수 있습니다. External ID키는 원본 이미지의 파일명을 담고 있으므로 요긴하게 쓸 수 있겠네요.
import imageio, requests
from matplotlib import pyplot as plt
Labeled_Data_Img = imageio.imread(json_data[0]['Labeled Data'])
print(Labeled_Data_Img.shape)
plt.imshow(Labeled_Data_Img)
plt.show()
print('원본 이미지 파일명 : ',json_data[0]['External ID']) # 원본 이미지 파일명
(1024, 1024, 3)

원본 이미지 파일명 : example-100647.jpg
Masks키는 클래스 라벨들의 바이너리 이미지를 담고 있습니다. eye와 같은 클래스 이름으로 접근해 각 클래스 바이너리 이미지의 url을 얻을 수 있습니다. 사실 각 바이너리 클래스 이미지는 바이너리 이미지 4개가 합쳐진 4채널로 구성되어 있지만 저희에게 필요한 것은 똑같은 4개의 채널 중 단 하나이기 때문에 [:,:,0]으로 접근해 한 개의 채널만 받아옵니다.
print(json_data[0]['Masks'])
{'eye': 'https://faas-gateway.labelbox.com/function/mask-exporter?'}
print(json_data[0]['Masks']['nose'])
https://faas-gateway.labelbox.com/function/mask-exporter?
fig = plt.figure()
rows = 2
cols = 2
i = 1
xlabels = ['xlabel', 'eye', 'nose', 'mouth', 'eyebrow']
for image_url in json_data[0]['Masks']:
ax = fig.add_subplot(rows, cols, i)
img_arr = imageio.imread(json_data[0]['Masks'][image_url])[:,:,0]
ax.imshow(img_arr, cmap='gray', vmin=0, vmax=255)
ax.set_xlabel(xlabels[i])
ax.set_xticks([]), ax.set_yticks([])
i+=1
plt.show()

이제 필요한 딕셔너리 키만 모아 새로운 딕셔너리를 만들겠습니다. StyleGAN으로 만들어진 TWDNE 데이터셋 특성상 간혹 눈이나 코, 입이 없거나 상식적으로 있을 수 없는 위치에 생성된 이미지가 존재하기 때문에, 라벨링을 도와주신 분들께 이상하게 생긴 클래스나 이미지는 스킵하라고 말씀드린 상황입니다. 따라서 키가 없는 클래스가 존재할 수 있으므로, 반드시 네 개의 클래스가 모두 존재하는 키만 가져옵니다.
ImgName, OriginalImg, Category 세 개의 키를 갖는 새 딕셔너리를 만든 후 entireData 리스트에 append합니다.
# 필요한 딕셔너리 키만 모아 새로운 리스트 만들기
entireData = []
for i in range(len(json_data)):
if 'External ID' in json_data[i] and 'Labeled Data' in json_data[i] and 'Masks' in json_data[i]:
if 'eye' in json_data[i]['Masks'] and 'nose' in json_data[i]['Masks'] and 'mouth' in json_data[i]['Masks'] and 'eyebrow' in json_data[i]['Masks']:
_newdict = dict(ImgName = json_data[i]['External ID'],
OriginalImg = json_data[i]['Labeled Data'],
Category = json_data[i]['Masks'])
entireData.append(_newdict)
else:
i+=1
entireData[0]
{'ImgName': 'example-100647.jpg',
'OriginalImg': 'https://storage.labelbox.com/ck0c31n8b839z0',
'Category': {'eye': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'nose': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'mouth': 'https://faas-gateway.labelbox.com/function/mask-exporter?',
'eyebrow': 'https://faas-gateway.labelbox.com/function/mask-exporter?'}}
한 장의 이미지로 만들기
다음으로, 위에서 만든 entireData을 활용해 바이너리 이미지들을 다운로드받고 색깔을 입혀 한 장의 이미지로 만드는 과정을 소개합니다.
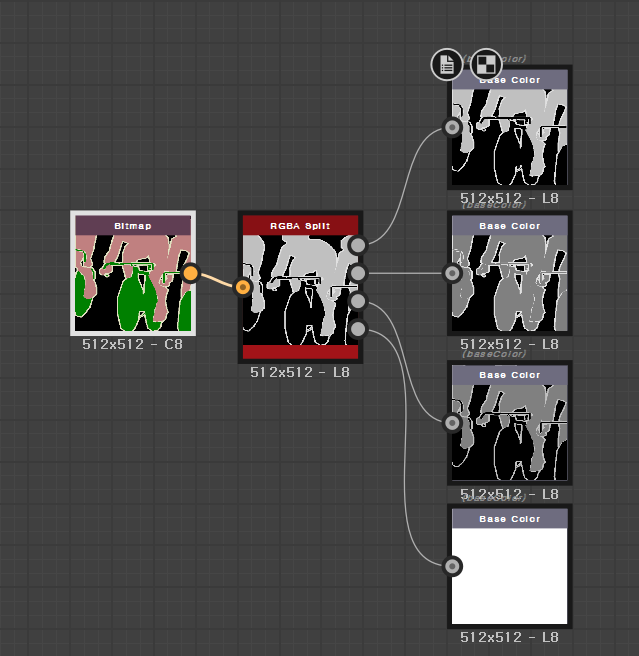
PASCAL-VOC 데이터셋의 라벨 이미지 한 장을 뜯어보면 위와 같이 3채널 컬러 8비트 이미지로 인코딩되어 있음을 알 수 있습니다. 저희는 위에서 본 네 장의 바이너리 이미지들을 위 이미지와 같이 바꾸어 주어야 합니다. 우선 원본 이미지는 requests를 이용해 다운로드받고, 바이너리 이미지들은 imageio를 이용해 image array로 받습니다.
uint8 타입의 빈 3채널 numpy array output을 만들어 준 다음 각 채널의 위치에 바이너리 이미지를 더해 Red, Green, Blue, Yellow 네 개의 색상으로 칠합니다.
# File Download and check NotExistFile ckeck Function
import imageio, time, random, requests
import numpy as np
from PIL import Image
from tqdm import tqdm_notebook
def searchIsImgExist(entireData, dataset_img_savepath, dataset_cat_savepath):
existList = []
NOTexistList = []
for j in range(len(entireData)):
basesavename = entireData[j]['ImgName'].split('.')[0]
imgsavepath = dataset_img_savepath + basesavename + '-original.jpg'
catsavepath = dataset_cat_savepath + basesavename + '-category.png'
if os.path.isfile(imgsavepath) and os.path.isfile(catsavepath):
existList.append(entireData[j])
else:
NOTexistList.append(entireData[j])
print(str(len(existList)) + ' files exist.')
print(str(len(NOTexistList)) + ' files does not exist.')
return NOTexistList
def searchMissingImg(entireData, dataset_img_savepath, dataset_cat_savepath):
missingFileList = []
for i in range(len(entireData)):
basesavename = entireData[i]['ImgName'].split('.')[0]
imgsavepath = dataset_img_savepath + basesavename + '-original.jpg'
catsavepath = dataset_cat_savepath + basesavename + '-category.png'
if os.path.isfile(catsavepath) or os.path.isfile(catsavepath):
continue
else:
missingFileList.append(entireData[i])
print(str(len(missingFileList)) + ' files are missing.')
return missingFileList
def imgDownloader(flag, entireData, dataset_img_savepath, dataset_cat_savepath):
if flag == 'downloadNotExistFile':
ImgList = searchIsImgExist(entireData, dataset_img_savepath, dataset_cat_savepath)
total = tqdm_notebook(range(len(ImgList)), desc = 'Download in Progress : ')
print("Current Flag : ", flag)
elif flag == 'downloadMissingImg':
ImgList = searchMissingImg(entireData, dataset_img_savepath, dataset_cat_savepath)
total = tqdm_notebook(range(len(ImgList)), desc = 'Download in Progress : ')
print("Current Flag : ", flag)
else:
print("Wrong flag. Check again.")
raise NotImplementedError
for i in total:
basesavename = ImgList[i]['ImgName'].split('.')[0]
imgsavepath = dataset_img_savepath + basesavename + '-original.jpg'
catsavepath = dataset_cat_savepath + basesavename + '-category.png'
if os.path.isfile(imgsavepath) and os.path.isfile(catsavepath):
continue
else:
time.sleep(random.randint(1,3))
OriginalImg_url = ImgList[i]['OriginalImg']
CatImg_eye_url = ImgList[i]['Category']['eye']
CatImg_nose_url = ImgList[i]['Category']['nose']
CatImg_mouth_url = ImgList[i]['Category']['mouth']
CatImg_eyebrow_url = ImgList[i]['Category']['eyebrow']
originalImg_response = requests.get(OriginalImg_url)
with open(imgsavepath, "wb") as outfile:
outfile.write(originalImg_response.content)
CatImg_eye = imageio.imread(CatImg_eye_url)[:,:,0]
CatImg_nose = imageio.imread(CatImg_nose_url)[:,:,0]
CatImg_mouth = imageio.imread(CatImg_mouth_url)[:,:,0]
CatImg_eyebrow = imageio.imread(CatImg_eyebrow_url)[:,:,0]
height, width = CatImg_eye.shape
output = np.zeros((height, width, 3), dtype = np.uint8)
output[..., 0] += CatImg_eye # Red
output[..., 1] += CatImg_nose # Green
output[..., 2] += CatImg_mouth # Blue
output[..., 0] += CatImg_eyebrow # Yellow
output[..., 1] += CatImg_eyebrow # Yellow
FinalCatImg = Image.fromarray(output)
FinalCatImg = FinalCatImg.convert("P", palette=Image.ADAPTIVE, colors=8)
FinalCatImg.save(catsavepath)
다운로드를 받는 중 서버 상황에 따라 404에러나 Bad request 에러가 발생할 수 있기 때문에 imgDownloader함수는 'downloadNotExistFile'와 'downloadMissingImg'플래그를 설정할 수 있도록 합니다. 'downloadNotExistFile' 플래그는 존재하지 않는 파일을 다운로드하고, 'downloadMissingImg'플래그는 중간에 에러가 발생해 셀이 꺼진 경우 반복 실행해 빠진 이미지를 찾은 후 해당 이미지만 다운로드할 수 있도록 합니다. (사실 HTTP 에러 예외처리를 넣어 주었어야 하지만 이미지 장수가 많지 않아 그냥 'downloadMissingImg'을 여러번 반복했습니다.)
# Download img files
imgDownloader('downloadNotExistFile', entireData, dataset_img_savepath, dataset_cat_savepath)
0 files exist.
547 files does not exist.
HBox(children=(IntProgress(value=0, description='Download in Progress : ', max=547, style=ProgressStyle(descri…
Current Flag : downloadNotExistFile
---------------------------------------------------------------------------
# Search missing files and download them.
imgDownloader('downloadMissingImg', entireData, dataset_img_savepath, dataset_cat_savepath)
439 files are missing.
HBox(children=(IntProgress(value=0, description='Download in Progress : ', max=439, style=ProgressStyle(descri…
Current Flag : downloadMissingImg
---------------------------------------------------------------------------
Segment map이 잘 저장되었는지 세 장 정도 뽑아 확인해 보겠습니다.
import cv2, os
from matplotlib import pyplot as plt
import random
fig = plt.figure()
rows = 1
cols = 3
i = 1
# Select 3 random files
randomFiles = []
for i in range(3):
randomFiles.append(random.choice(os.listdir(dataset_cat_savepath)))
# Plot 3 image files
plt.subplots_adjust(right = 1.5)
for cat_image in randomFiles:
img = cv2.imread(os.path.join(dataset_cat_savepath, cat_image))
ax = fig.add_subplot(rows, cols, i-1)
ax.imshow(img)
ax.set_xlabel(str(cat_image)+'\n'+str(img.shape))
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
ax.set_xticks([]), ax.set_yticks([])
i+=1
plt.show()

원하는 그림이 나오네요! 혹시 모르니 가로 세로 비율이 같은지(사실 Deeplab은 가로세로 비율이 들쭉날쭉해도 되지만 제 데이터셋은 애니메이션 얼굴만 담기 위해 1:1로 통일했습니다.), 3채널이 온전히 존재하는지 확인해 보겠습니다.
# Check anomaly images
import cv2
# data path
dataset_img_savepath_list = os.listdir(dataset_img_savepath)
dataset_cat_savepath_list = os.listdir(dataset_cat_savepath)
if len(dataset_img_savepath_list) == len(dataset_cat_savepath_list):
tbar = tqdm_notebook(range(len(dataset_img_savepath_list)), desc='\r')
for i in tbar:
# get path of original and category images
img_image_path = os.path.join(dataset_img_savepath, dataset_img_savepath_list[i])
img_cat_path = os.path.join(dataset_cat_savepath, dataset_cat_savepath_list[i])
# open original and category images
img_image = cv2.imread(img_image_path, cv2.IMREAD_COLOR)
cat_image = cv2.imread(img_cat_path, cv2.IMREAD_COLOR)
img_c, img_w, img_h = img_image.shape
cat_c, cat_w, cat_h = cat_image.shape
if img_c == img_w and img_h == 3:
continue
elif cat_c == cat_w and cat_h == 3:
continue
else:
print('This original image is broken : ', img_image_path)
print('This category image is broken : ', img_cat_path)
print('Whole images are passed. No images are broken.')
else:
print('Length of dataset_img_savepath_list and dataset_cat_savepath_list does not match.' )
raise NotImplementedError
이제 딕셔너리에서 파일 이름만 따로 뽑아 trainset, validationset, testset으로 일정 비율에 따라 나눠 저장하겠습니다.
import numpy as np
from sklearn.model_selection import train_test_split
basenameList = []
def txtWriter(basenamelist, path):
txt = open(path, 'w')
for i in range(len(basenamelist)):
txt.write('%s\n' %basenamelist[i])
txt.close()
for i in range(len(entireData)):
basenameList.append(entireData[i]['ImgName'].split('.')[0])
train, val = train_test_split(basenameList, train_size = 0.8, random_state = 20191008)
val, test = train_test_split(val, train_size = 0.5, random_state = 20191008)
print(len(train))
print(len(val))
print(len(test))
txtWriter(train, os.path.join(dataset_txt_savepath, 'train.txt'))
txtWriter(val, os.path.join(dataset_txt_savepath, 'val.txt'))
txtWriter(test, os.path.join(dataset_txt_savepath, 'test.txt'))
437
55
55
컬러 팔레트를 새로 만들어 인코딩하기
하지만 지금까지 만든 이미지들을 그대로 학습에 사용하면 제대로 된 학습이 이루어지지 않습니다.
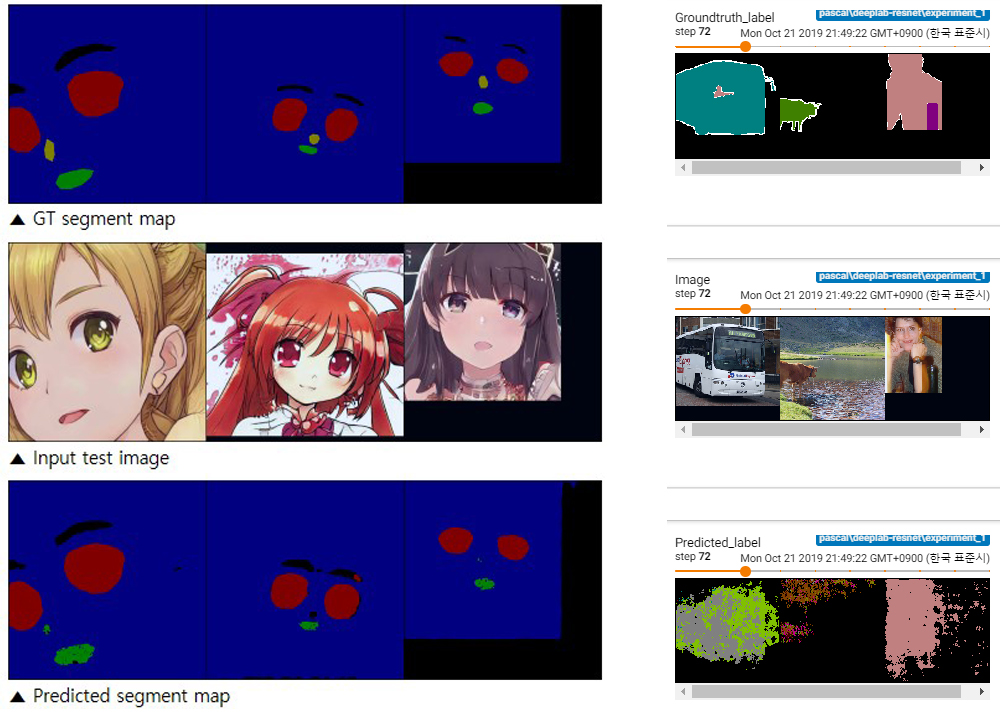
학습이 되긴 되지만 정답 그리고 결과 이미지가 무언가 이상하게 디코딩되는 것을 확인할 수 있습니다. 오른쪽이 PASCAL-VOC로 정상 학습 중인 상태의 이미지이고, 왼쪽이 지금까지 저희가 만든 이미지로 학습 중인 모습입니다. 어딘지 모르게 클래스 순서가 뒤바뀐 느낌이 들죠. 이는 png 컬러맵이 달라 발생하는 문제로, 저희의 클래스에 맞게 컬러 팔레트를 새로 만들어 인코딩해 주어야 학습에 문제가 발생하지 않습니다. 지금부터는 저희 클래스 컬러에 맞게 팔레트를 새로 만들어 다시 인코딩해 보겠습니다.
PASCAL-VOC처럼 테두리 만들기
팔레트를 새로 만들기 전, 내친김에 PASCAL-VOC 데이터셋의 정답 이미지처럼 클래스 세그먼트 테두리에 다른 컬러를 입혀 보겠습니다. PASCAL-VOC데이터셋의 정답 이미지엔 void라는 이름의 희끄무레한 클래스가 들어가 있습니다. 지금까지 만든 이미지를 활용해 void 클래스를 만들어 보겠습니다.

import cv2, os
import numpy as np
from matplotlib import pyplot as plt
parent_dir = os.path.abspath(os.getcwd() + "/../")
dataset_cat_savepath = os.path.join(os.path.abspath(os.getcwd() + "/../../../"), 'AnimFaceSeg_poly/category/')
# 전체 파일이름 리스트
entireCatImgPathList = os.listdir(dataset_cat_savepath)
entireCatImgPathList
['example-100002-category.png',
(...),
'example-10942-category.png']
이미지를 그레이스케일로 바꾼 후 혹시나 있을지 모를 0이 아닌 값을 모두 1로 바꾸어 줍니다. dilation 연산을 수행하기 전 이미지를 미리 512X512로 다운스케일해 퀄리티가 떨어지는 것을 방지하고, 바이너리 이미지에 대해 확장 연산을 세번 정도 반복 수행해 원본 이미지보다 뚱뚱한 이미지를 만듭니다. 이후 원본 이미지를 빼면 테두리를 얻을 수 있습니다.
이제 이 테두리에 색깔을 입힐 수 있습니다.
def addEdge2Img(img_path, isfig=False, outerlineColor=None, changebgColor=(False, None)):
# color = None인경우 white(255, 255, 255)
img_BGR = cv2.imread(img_path, cv2.IMREAD_COLOR)
img_BGR_resize = cv2.resize(img_BGR, dsize=(512, 512), interpolation=cv2.INTER_NEAREST)
img_grayscale = cv2.cvtColor(img_BGR_resize, cv2.COLOR_BGR2GRAY) # BGR 이미지를 그레이스케일로 변환.
b, g, r = cv2.split(img_BGR_resize)
img_gray_white = np.where(img_grayscale != 0, 255, img_grayscale).astype(np.uint8) # 0이 아닌 index를 모두 1로 바꾸기
k = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3)) # 확장(dilation) 연산을 위한 커널 정의
img_gray_white_dst = cv2.dilate(img_gray_white, k, iterations=5) # 확장 연산을 세번 반복 수행
outer_edge = img_gray_white_dst - img_gray_white
if outerlineColor != None: # Custom outer line color
edge_r = np.where(outer_edge != 0, outerlineColor[0], outer_edge).astype(np.uint8)
edge_g = np.where(outer_edge != 0, outerlineColor[1], outer_edge).astype(np.uint8)
edge_b = np.where(outer_edge != 0, outerlineColor[2], outer_edge).astype(np.uint8)
r = r + edge_r
g = g + edge_g
b = b + edge_b
if changebgColor == None: # add 'other' class to background
output = cv2.merge((r, g, b))
elif changebgColor[0] == True:
otherClassmap = np.where(img_gray_white_dst == 0, changebgColor[1], 0).astype(np.uint8)
r = r + otherClassmap
g = g + otherClassmap
b = b + otherClassmap
output = cv2.merge((r, g, b))
else:
print("Wrong changebgColor argument input")
raise NotImplementedError
if isfig == True:
print(output.shape)
plt.imshow(output)
plt.xticks([]) # x축 눈금
plt.yticks([]) # y축 눈금
plt.show()
return output
# Test with single image
testImg_whiteline = addEdge2Img(img_path=os.path.join(dataset_cat_savepath, entireCatImgPathList[0]), isfig=True,
outerlineColor=None, changebgColor=None) # 테두리 없음, 배경클래스 없음
testImg_whiteline_and_otherclass = addEdge2Img(img_path=os.path.join(dataset_cat_savepath, entireCatImgPathList[0]), isfig=True,
outerlineColor=None, changebgColor=(True, 192)) # 테두리 없음, 배경색 192로 변경
testImg_ivoryline_and_otherclass = addEdge2Img(img_path=os.path.join(dataset_cat_savepath, entireCatImgPathList[0]), isfig=True,
outerlineColor=(224, 224, 192), changebgColor=(True, 192)) # 아이보리색 테두리, 배경색 192로 변경
(512, 512, 3)

(512, 512, 3)

(512, 512, 3)

컬러 팔레트 새로 만들어 인코딩하기
이제 다시 돌아가 저희만의 팔레트를 만드는 작업을 계속 하겠습니다. 저는 굳이 void 클래스가 필요 없으므로, background를 포함해 총 5개의 클래스에 대해 팔레트를 정의해 주었습니다.
import itertools
from PIL import Image
# Add color code for class
palette = [(0, 0, 0), (128, 0, 0), (0, 128, 0), (0, 0, 128), (128, 128, 0)]
while len(palette) < 256:
palette.append((0, 0, 0))
flat_palette = list(itertools.chain(*palette))
palette_img = Image.new('P', (1, 1), 0)
palette_img.putpalette(flat_palette)
이후 위에서 만든 팔레트를 이용해 quantize를 수행해 주면 됩니다. 함수 이름에서 눈치채셨을지 모르겠지만, 사전에 이미지에 포함되는 컬러의 색상을 모두 알고 있다면 팔레트를 만들어 이미지의 사이즈를 줄일 수 있습니다. 팔레트가 미리 정의되어 있다면 8비트까지 이미지를 줄이는 것이 가능하기 때문입니다.
from tqdm import tqdm_notebook
from PIL import Image
total = tqdm_notebook(range(len(entireCatImgPathList)), desc = 'Conversion in Progress : ')
for i in total:
# 1) Add white outer line with dilation 2) add other class label color to bg
convertedImg = addEdge2Img(img_path=os.path.join(dataset_cat_savepath, entireCatImgPathList[i]),isfig=False,
outerlineColor=None, changebgColor=None)
convertedImg_arr = Image.fromarray(convertedImg)
# .png 포맷 규칙과 전체 컬러 개수에 맞게 팔레트 설정
convertedImg_arr = convertedImg_arr.quantize(palette=palette_img)
convertedImg_arr.save(os.path.join(dataset_cat_savepath, entireCatImgPathList[i]))
HBox(children=(IntProgress(value=0, description='Conversion in Progress : ', max=150, style=ProgressStyle(desc…
팔레트가 잘 적용되었는지 확인해 보기
이미지의 메타 정보를 확인하는 방법은 여러 가지가 있습니다만 저는 ImageMagik을 선호합니다. 셋업하는 방법은 공식 홈페이지나 다른 분들 블로그를 참고하시기 바랍니다.
magick identify -verbose 파일명 명령어를 사용하면 png 이미지의 모든 메타 정보를 읽어낼 수 있습니다. Type: Palette, Colors: 5, Colormap 항목을 통해 저희가 원하는 색상으로 이미지가 인코딩되어 저장되었음을 확인해 볼 수 있습니다.
!magick identify -verbose C:\Users\MGL\AnimFaceSeg_poly\category\example-10198-category.png
Image: C:\Users\MGL\AnimFaceSeg_poly\category\example-10198-category.png
Format: PNG (Portable Network Graphics)
Mime type: image/png
Class: PseudoClass
Geometry: 512x512+0+0
Units: Undefined
Colorspace: sRGB
Type: Palette
Base type: Undefined
Endianess: Undefined
Depth: 8-bit
Channel depth:
Red: 8-bit
Green: 8-bit
Blue: 8-bit
Channel statistics:
Pixels: 262144
Red:
min: 0 (0)
max: 128 (0.501961)
mean: 4.89111 (0.0191808)
standard deviation: 24.5386 (0.0962297)
kurtosis: 21.2095
skewness: 4.81761
entropy: 0.234033
Green:
min: 0 (0)
max: 128 (0.501961)
mean: 2.19922 (0.00862439)
standard deviation: 16.6332 (0.0652284)
kurtosis: 53.2195
skewness: 7.43097
entropy: 0.125308
Blue:
min: 0 (0)
max: 128 (0.501961)
mean: 0.869141 (0.00340839)
standard deviation: 10.5117 (0.0412222)
kurtosis: 142.278
skewness: 12.0115
entropy: 0.0586678
Image statistics:
Overall:
min: 0 (0)
max: 128 (0.501961)
mean: 2.65316 (0.0104045)
standard deviation: 17.2278 (0.0675601)
kurtosis: 43.2655
skewness: 6.72796
entropy: 0.139336
Colors: 5
Histogram:
247880: ( 0, 0, 0) #000000 black
1780: ( 0, 0,128) #000080 navy
2467: ( 0,128, 0) #008000 green
7980: (128, 0, 0) #800000 maroon
2037: (128,128, 0) #808000 olive
Colormap entries: 256
Colormap:
0: ( 0, 0, 0,255) #000000FF black
1: (128, 0, 0,255) #800000FF maroon
2: ( 0,128, 0,255) #008000FF green
3: ( 0, 0,128,255) #000080FF navy
4: (128,128, 0,255) #808000FF olive
5: ( 0, 0, 0,255) #000000FF black
(...)
255: ( 0, 0, 0,255) #000000FF black
Rendering intent: Perceptual
Gamma: 0.454545
Version: ImageMagick 7.0.8-68 Q16 x64 2019-10-05 http://www.imagemagick.org