FacialLandmarkManga Dataset Simple EDA
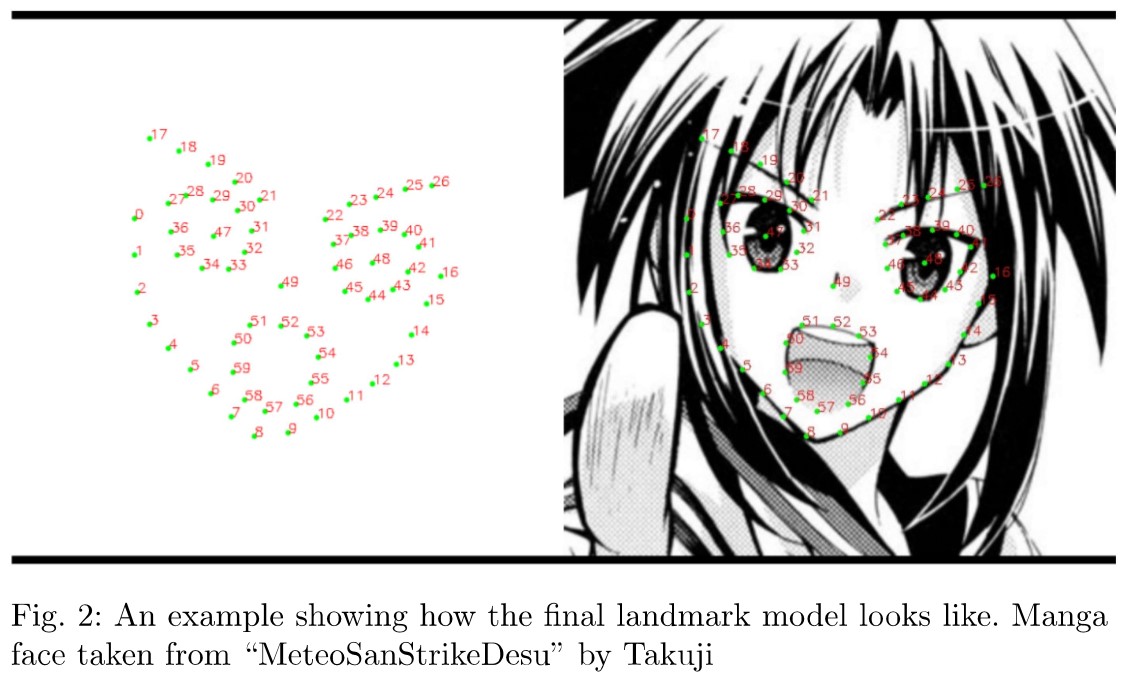
이번 포스트에서는 FacialLandmarkManga 데이터셋의 EDA를 수행해 봅니다.
FacialLandmarkManga 데이터셋은 Manga109 데이터셋에 facial landmark annotation을 추가한 데이터셋입니다. FacialLandmarkManga 데이터셋은 facial annotation 데이터(.json)만 제공하고 있으며, 해당 데이터셋을 원활히 학습에 사용하기 위해서는 Manga109 데이터셋이 추가로 필요합니다. 아마 저작권상의 이유로 따로 받아야 하는 것 같습니다.
Manga109 데이터셋을 다운받기 위해서는 도쿄대학교 Aizawa-Yamasaki Lab에 이메일을 보내 연구 목적의 허가를 받아야 하며, 허가 메일과 함께 3일 동안 사용 가능한 데이터셋 다운로드 링크를 제공해 줍니다. 혹시나 이미지 데이터셋이 필요하신 분들은 Manga109 공식 홈페이지에서 안내하는 방법대로 허가를 받으시면 됩니다. 이번 포스트에서는 FacialLandmarkManga 데이터셋만 갖고 EDA를 수행해 보았습니다.
1. 데이터셋 포맷 확인
먼저 작업 경로를 설정하고 데이터셋이 어떤 파일들을 포함하고 있는지 확인해 보겠습니다.
import os
import pandas as pd
from pandas import DataFrame
current_dir = os.getcwd()
parent_dir = os.path.abspath(current_dir + "/../../")
charfilepath = os.path.join(parent_dir, 'landmarksUser/')
entireFilesList = os.listdir(charfilepath)
print(entireFilesList[:3])
print(len(entireFilesList))
['user0_MeteoSanStrikeDesu_008_face01_x382y574w184h232.json', 'user0_MeteoSanStrikeDesu_015_face00_x514y302w132h136.json', 'user0_MeteoSanStrikeDesu_021_face00_x152y96w121h117.json']
2105
데이터셋은 .json파일들로만 구성되어 있습니다. 제일 먼저 해야 할 것은 파일 이름으로부터 캐릭터 이름만 분리해 분포를 확인해 보는 것입니다. split('_')을 활용하면 특정 문자를 기준으로 string을 쪼갤 수 있습니다. 쪼개져 반환된 리스트 중 캐릭터 이름은 두 번째 인덱스에 들어 있는 것을 확인할 수 있습니다.
entireFilesList[657].split('_')[1]
'OhWareraRettouSeitokai'
2. 캐릭터 이름별 빈도수 확인
각 .json파일들은 파일명에 캐릭터의 이름과 Manga109의 파일과 매칭되는 bounding box 정보(e.g. x382y574w184h232)를 담고 있습니다. 지금부터는 캐릭터 이름에 따른 등장 빈도를 세어 보겠습니다.
캐릭터의 등장 빈도를 세기 위해, 모든 파일 이름으로부터 캐릭터 이름만 분리합니다. collections모듈의 Counter를 활용하면 유니크한 값들의 빈도수를 확인할 수 있습니다. 캐릭터 이름에 따른 Count를 확인해 pandas dataframe을 생성합니다.
EntireCharList = []
for i in range(len(entireFilesList)):
EntireCharList.append(entireFilesList[i].split('_')[1])
print(EntireCharList[:3])
print(len(EntireCharList))
['MeteoSanStrikeDesu', 'MeteoSanStrikeDesu', 'MeteoSanStrikeDesu']
2105
from collections import Counter
df_charcount = pd.DataFrame.from_dict(Counter(EntireCharList), orient='index').reset_index()
df_charcount = df_charcount.rename(columns = {'index':'CharacterName', 0:'count'})
df_charcount
| CharacterName | count | |
|---|---|---|
| 0 | MeteoSanStrikeDesu | 75 |
| 1 | MiraiSan | 114 |
| 2 | MisutenaideDaisy | 94 |
| 3 | MomoyamaHaikagura | 78 |
| 4 | Nekodama | 104 |
| 5 | NichijouSoup | 127 |
| 6 | Ningyoushi | 103 |
| 7 | OhWareraRettouSeitokai | 124 |
| 8 | OL | 326 |
| 9 | ParaisoRoad | 53 |
| 10 | PikaruGenkiDesu | 99 |
| 11 | PlatinumJungle | 80 |
| 12 | PrayerHaNemurenai | 119 |
| 13 | PrismHeart | 114 |
| 14 | PsychoStaff | 124 |
| 15 | Raphael | 105 |
| 16 | RinToSiteSippuNoNaka | 154 |
| 17 | RisingGirl | 112 |
dataframe상으로 확인해 보아도 분포가 상당히 치우쳐 있음을 알 수 있습니다. 좀 더 직관적으로 확인해 보기 위해 차트를 그려 봅시다.
from matplotlib import pyplot as plt
import seaborn as sns
sns.set(rc={'figure.figsize':(15,5)}, font_scale = 1.5)
g = sns.barplot(x='CharacterName', y='count', data=df_charcount)
g = plt.setp(g.get_xticklabels(), rotation=90)
plt.show()
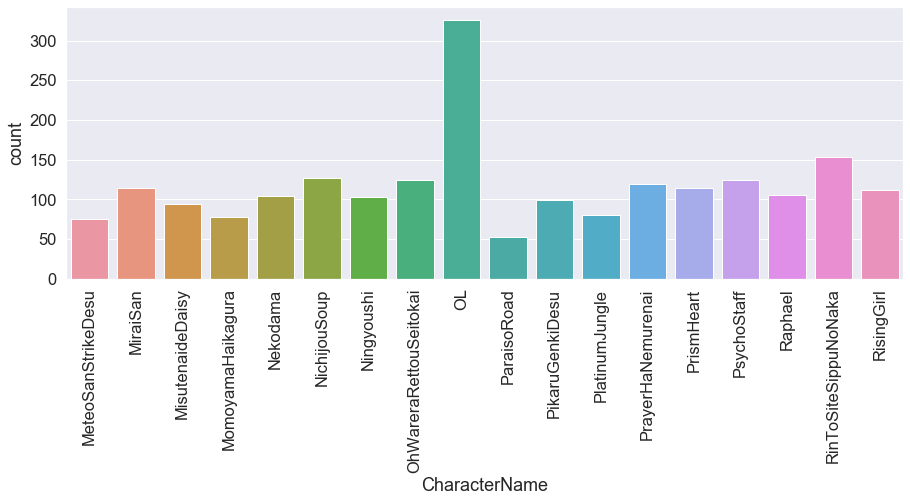
구도나 얼굴의 왜곡 정도가 만화의 컷마다 달라진다고는 하지만, 분포가 치우치면 빈도수가 잦은 캐릭터의 스타일 정보가 겹치게 되고, 따라서 특정 캐릭터에 쏠림 현상이 발생할 수 있습니다. 즉 Class imbalance 문제를 야기할 수 있으므로, 유의하여 샘플링을 할 필요가 있어 보입니다.
3. 캐릭터별 Emotion 분포 확인
FacialLandmarkManga 데이터셋의 각 .json파일은 "Emotions"라는 키를 갖고 있습니다. 해당 캐릭터의 감정 상태를 annotation한 것으로, 각 숫자가 어떤 표정을 의미하는지는 확인해 보지 않았습니다. 여기서는 오로지 분포만 확인해 보도록 합니다.
.json파일을 연 후 "Emotions"키로 접근하면 value를 가져올 수 있습니다.
import json
jsonpath = 'user0_MeteoSanStrikeDesu_008_face01_x382y574w184h232.json'
with open(jsonpath) as json_file:
json_data = json.load(json_file)
print(json_data['Emotions'])
1
이제 전체 2105개의 데이터 중 유니크한 캐릭터만 뽑아 정리해 보겠습니다. 파이썬 내장함수 set을 활용하면 유니크한 set을 추출할 수 있습니다.
uniqueCharNames = sorted(list(set(EntireCharList))) # 오름차순(A~Z)으로 리스트 정렬
print(uniqueCharNames)
print(len(uniqueCharNames))
['MeteoSanStrikeDesu', 'MiraiSan', 'MisutenaideDaisy', 'MomoyamaHaikagura', 'Nekodama', 'NichijouSoup', 'Ningyoushi', 'OL', 'OhWareraRettouSeitokai', 'ParaisoRoad', 'PikaruGenkiDesu', 'PlatinumJungle', 'PrayerHaNemurenai', 'PrismHeart', 'PsychoStaff', 'Raphael', 'RinToSiteSippuNoNaka', 'RisingGirl']
18
유니크한 캐릭터는 총 18명으로 확인됩니다. 이제 각 캐릭터가 갖고 있는 "Emotions"의 종류와 그 수를 세어 보겠습니다. 유니크한 캐릭터 단위로 반복문을 수행하되 emotion type별로 그 횟수를 세어 dataframe을 생성한 후 emotiondfList 리스트에 append합니다. 아래에서 이렇게 만들어진 dataframe을 활용해 시각화를 할 것입니다.
index = 0
tempList = []
emotiondfList = []
for i in range(len(uniqueCharNames)):
emotions_per_one_char = []
for jsonpath in entireFilesList:
if uniqueCharNames[i] in jsonpath:
selectedjsonpath = os.path.join(charfilepath, jsonpath)
with open(selectedjsonpath) as json_file:
json_data = json.load(json_file)
emotions_per_one_char.append(json_data['Emotions'])
print('charname:' + str(uniqueCharNames[i]))
df_emotioncount = pd.DataFrame.from_dict(Counter(emotions_per_one_char), orient='index').reset_index()
df_emotioncount = df_emotioncount.rename(columns = {'index':'emotiontype', 0:'emotioncount'})
emotiondfList.append(df_emotioncount)
print(df_emotioncount, '\n')
charname:MeteoSanStrikeDesu
emotiontype emotioncount
0 1 16
1 2 20
2 8 11
3 64 10
4 4 7
5 16 5
6 32 4
7 0 2
charname:MiraiSan
emotiontype emotioncount
0 1 49
1 2 31
2 0 2
3 8 11
4 16 7
5 32 8
6 4 6
charname:MisutenaideDaisy
emotiontype emotioncount
0 1 31
1 64 17
2 8 14
3 2 13
4 4 8
5 16 8
6 32 1
7 0 2
charname:MomoyamaHaikagura
emotiontype emotioncount
0 4 5
1 2 16
2 1 31
3 8 9
4 64 7
5 16 8
6 0 1
7 32 1
charname:Nekodama
emotiontype emotioncount
0 2 23
1 4 16
2 8 22
3 0 4
4 64 12
5 1 14
6 16 12
7 32 1
charname:NichijouSoup
emotiontype emotioncount
0 1 36
1 2 35
2 8 22
3 4 14
4 16 10
5 32 5
6 0 3
7 64 2
charname:Ningyoushi
emotiontype emotioncount
0 1 47
1 16 14
2 8 16
3 2 6
4 4 13
5 0 2
6 32 2
7 64 3
charname:OL
emotiontype emotioncount
0 1 108
1 2 93
2 8 34
3 0 9
4 64 22
5 32 16
6 16 34
7 4 10
charname:OhWareraRettouSeitokai
emotiontype emotioncount
0 0 3
1 2 20
2 1 41
3 16 15
4 8 22
5 4 11
6 64 10
7 32 2
charname:ParaisoRoad
emotiontype emotioncount
0 64 8
1 1 14
2 2 18
3 16 4
4 4 5
5 8 3
6 0 1
charname:PikaruGenkiDesu
emotiontype emotioncount
0 2 19
1 8 18
2 1 45
3 16 8
4 32 2
5 64 2
6 4 5
charname:PlatinumJungle
emotiontype emotioncount
0 8 9
1 16 12
2 64 4
3 32 1
4 1 40
5 4 9
6 2 5
charname:PrayerHaNemurenai
emotiontype emotioncount
0 8 9
1 32 5
2 16 29
3 64 4
4 4 12
5 1 46
6 2 13
7 0 1
charname:PrismHeart
emotiontype emotioncount
0 1 44
1 64 1
2 2 32
3 16 12
4 4 8
5 8 14
6 32 3
charname:PsychoStaff
emotiontype emotioncount
0 1 34
1 4 15
2 64 16
3 2 18
4 8 31
5 0 1
6 16 3
7 32 6
charname:Raphael
emotiontype emotioncount
0 1 61
1 16 12
2 2 25
3 8 3
4 64 1
5 4 1
6 0 2
charname:RinToSiteSippuNoNaka
emotiontype emotioncount
0 4 21
1 0 4
2 1 76
3 64 15
4 16 17
5 8 10
6 32 2
7 2 9
charname:RisingGirl
emotiontype emotioncount
0 32 2
1 4 3
2 1 29
3 2 34
4 16 18
5 64 11
6 0 3
7 8 12
emotiondfList 리스트의 요소를 하나 찍어보면 아래와 같이 유니크한 캐릭터의 emotiontype과 그 횟수가 담긴 dataframe이 출력됩니다.
emotiondfList[0]
| emotiontype | emotioncount | |
|---|---|---|
| 0 | 1 | 16 |
| 1 | 2 | 20 |
| 2 | 8 | 11 |
| 3 | 64 | 10 |
| 4 | 4 | 7 |
| 5 | 16 | 5 |
| 6 | 32 | 4 |
| 7 | 0 | 2 |
위에서 만들어진 emotiondfList의 각 dataframe에 캐릭터의 이름 column을 추가해 주겠습니다.
for i in range(len(uniqueCharNames)):
emotiondfList[i]["charname"] = uniqueCharNames[i]
emotiondfList[1]
| emotiontype | emotioncount | charname | |
|---|---|---|---|
| 0 | 1 | 49 | MiraiSan |
| 1 | 2 | 31 | MiraiSan |
| 2 | 0 | 2 | MiraiSan |
| 3 | 8 | 11 | MiraiSan |
| 4 | 16 | 7 | MiraiSan |
| 5 | 32 | 8 | MiraiSan |
| 6 | 4 | 6 | MiraiSan |
그리고, 유니크한 캐릭터의 명수에 맞게 올바르게 dataframe들이 생성되었는지 길이를 확인해 봅니다. 이후 pd.concat을 활용해 하나의 dataframe으로 합쳐 줍니다.
print(len(emotiondfList))
18
concated_emotiondfList = pd.concat(emotiondfList)
concated_emotiondfList.head(10)
| emotiontype | emotioncount | charname | |
|---|---|---|---|
| 0 | 1 | 16 | MeteoSanStrikeDesu |
| 1 | 2 | 20 | MeteoSanStrikeDesu |
| 2 | 8 | 11 | MeteoSanStrikeDesu |
| 3 | 64 | 10 | MeteoSanStrikeDesu |
| 4 | 4 | 7 | MeteoSanStrikeDesu |
| 5 | 16 | 5 | MeteoSanStrikeDesu |
| 6 | 32 | 4 | MeteoSanStrikeDesu |
| 7 | 0 | 2 | MeteoSanStrikeDesu |
| 0 | 1 | 49 | MiraiSan |
| 1 | 2 | 31 | MiraiSan |
위에서 만들어진 dataframe을 이용해 시각화를 진행해 봅니다. 여러 그래프가 캐릭터별로 찍히면 혼잡하므로, seaborn의 FacetGrid를 이용해 한 이미지에 모든 그래프를 출력합니다. 혹시 개별 캐릭터 단위로 출력하고 싶으신 분들을 위해 캐릭터별 그래프를 출력하는 코드도 주석 처리를 하여 아래 셀에 남겨 두었습니다.
# 캐릭터별 개별 그래프를 출력하고 싶은 경우 실행합니다.
# sns.set(rc={'figure.figsize':(5,5)}, font_scale = 1.5)
# for i in range(len(emotiondfList)):
# plt.title(uniqueCharNames[i])
# g = sns.barplot(x='emotiontype', y='emotioncount', data=emotiondfList[i])
# g = plt.setp(g.get_xticklabels(), rotation=0)
# plt.ylim(0, 110)
# plt.show()
facet = sns.FacetGrid(concated_emotiondfList, col = 'charname', col_wrap=6, aspect = 1.5, hue ='charname')
facet.map(sns.barplot, 'emotiontype', 'emotioncount').set_titles("{col_name}")
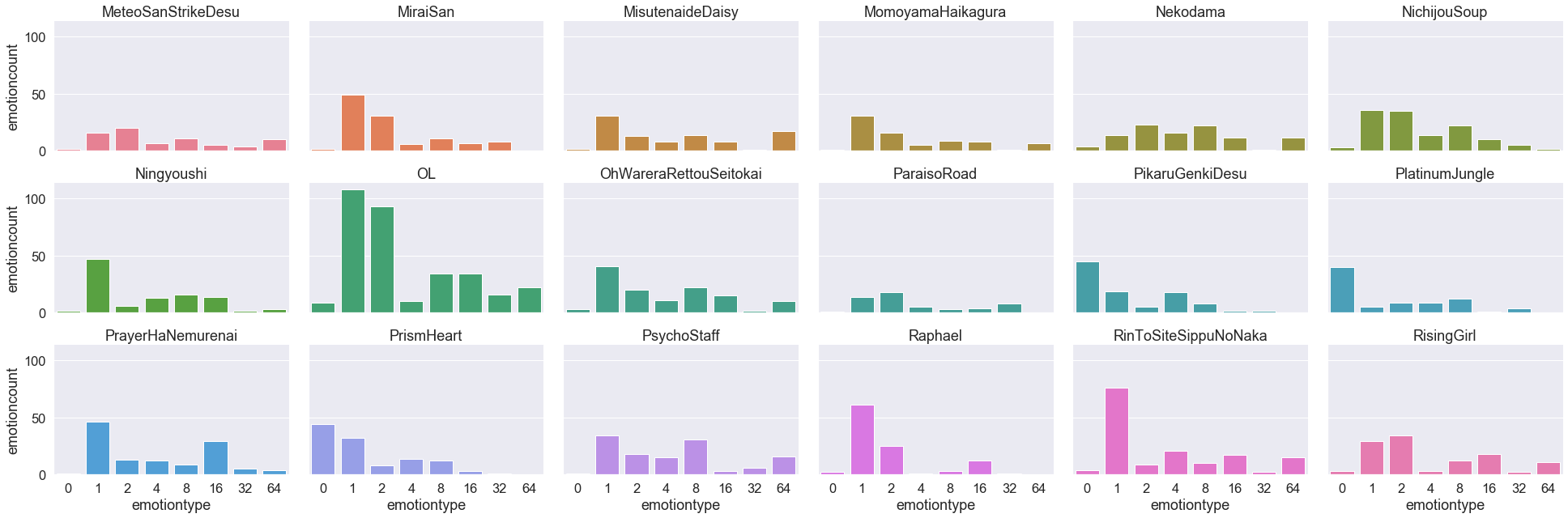
그래프를 통해 특정 emotion에 대한 Landmark 정보가 지나치게 많아 캐릭터 감정 인식 연구에 본 데이터셋을 활용 시 샘플링에 유의가 필요할 것으로 보입니다. 아울러 오래된 작화 스타일을 갖는 18명의 캐릭터로 2105여 개의 facial landmark 데이터셋을 구성했기 때문에 현대의 스타일과 다소 차이가 존재합니다. 하지만 새로운 데이터셋을 만들기엔 저작권 문제를 회피할 수 없기 때문에, 보다 자유로운 연구를 위해서는 GAN과 같은 Generative model을 활용한 synthesized dataset이 필요할 것으로 생각됩니다.