MLDLStudy
다양한 ML/DL 스터디를 하며 배운 경험들을 나눕니다.
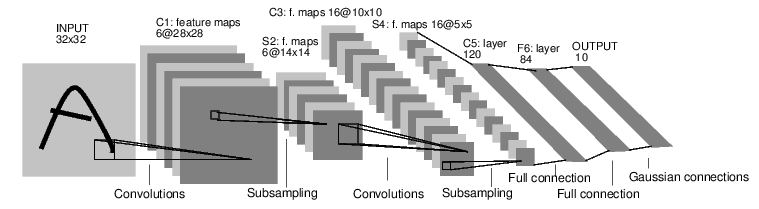
(Deeperence 1기)Pytorch CNN MNIST Tutorial
숭실대학교 머신러닝 소모임 Deeperence에서 비전 인공지능 입문자를 대상으로 진행했던 세미나 노트북을 공유드립니다. Continue reading (Deeperence 1기)Pytorch CNN MNIST Tutorial

(KR-KaggleKernelTranscription)Mercedes EDA & XGBoost Starter (~0.55)
Mercedes-Benz Greener Manufacturing 대회의 인기 커널 중 하나를 번역했습니다. 이번 포스트에선 간단한 EDA, XGBoost 모델을 통해 submit 데이터를 만드는 과정에 대해 알아봅니다. Continue reading (KR-KaggleKernelTranscription)Mercedes EDA & XGBoost Starter (~0.55)
(KR-KaggleKernelTranscription)Simple Exploration Notebook - Mercedes
Mercedes-Benz Greener Manufacturing 대회의 인기 커널 중 하나를 번역했습니다. 이번 포스트에선 높은 분류 성능을 자랑하기보다, EDA를 수행한 후 XGBoost와 Ramdom Forest모델을 활용하여 feature importance를 찾는 방법에 대해 알아봅니다. Continue reading (KR-KaggleKernelTranscription)Simple Exploration Notebook - Mercedes

(KR-KaggleKernelTranscription)Titanic Top 4% with ensemble modeling
데이터 사이언스에 입문하시는 분들이라면 한번쯤은 마주치는 타이타닉 대회의 유명 커널을 소개합니다. 이번 글에서는 YASSINE GHOUZAM의 “Titanic Top 4% with ensemble modeling” 포스트를 번역했습니다. Continue reading (KR-KaggleKernelTranscription)Titanic Top 4% with ensemble modeling
(KR-KaggleKernelTranscription)Introduction to EnsemblingStacking in Python
학습 모델을 앙상블(결합)하는 방법, 특히 스태킹(stacking)이라고 알려진 앙상블 기법을 캐글 대회에 사용한 노트북을 번역했습니다. Continue reading (KR-KaggleKernelTranscription)Introduction to EnsemblingStacking in Python

Calculate CNN Output Size
Convolution output size와 RF(Receptive Field) Size를 계산하는 공식입니다. Continue reading Calculate CNN Output Size

(BookSummary) Ensemble Method (「기계학습」, 오일석 저)
오일석 저자의 ‘기계학습’ 챕터 12의 내용 순서에 따라 앙상블 기법을 사용하는 목적과 이유, 리샘플링 메소드와 함께 결정트리, 랜덤포레스트, 앙상블 결합 등의 다양한 내용들을 정리했습니다. Continue reading (BookSummary) Ensemble Method (「기계학습」, 오일석 저)

(PaperReview) "U-GAT-IT" unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation
도메인 간의 매핑 함수를 학습해 신기한 이미지를 만들고자 하는 Image to Image translation 분야의 새로운 시도가 계속되고 있는 가운데 NCSOFT의 김준호님이 1저자로 참여한 U-GAT-IT은 AdaLIN이라는 새로운 정규화 기법을 제안하고 CAM(Class Activation Map)과 Attention 구조의 적용으로 도메인에 따라서 모델의 구조 변경이나 하이퍼파라미터 변경 없이도 유연한 shape 및 texture 변형이 가능케 하는 새로운 방법을 소개합니다. Continue reading (PaperReview) "U-GAT-IT" unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation

(PaperReview) Towards Foveated Rendering for Gaze-Tracked Virtual Reality
본 논문은 VR환경에서 렌더링 연산량 절감을 시도하는 과정에서 함께 발생하는 알리아싱 문제를 해결하고자 합니다. Non-foveated rendering 화상과 유사한 품질을 가진 결과를 VR 환경에서 도출하고자 하고, 이를 위해 다양한 foveation 기술을 실험할 수 있는 샌드박스를 만들고 테스트하며 기존 foveated renderer의 개선 방안을 모색했습니다. Continue reading (PaperReview) Towards Foveated Rendering for Gaze-Tracked Virtual Reality

(PaperReview) Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder
MC Rendering에 필연적으로 존재하는 noise를 denoising하기 위한 연구가 지금까지 계속되어 왔지만, Temporal artifact를 비롯한 다양한 문제들로 Offline rendering에 비해 썩 좋지 않은 결과물을 보여 왔습니다. NVIDIA는 Denoising AutoEncoder에 Recurrent connection 구조를 적용한 모델이 Real-time Monte Carlo Rendering Sequence의 노이즈 제거에 효과적임을 보여 주었습니다. Continue reading (PaperReview) Reconstruction of Monte Carlo Image Sequences using a Recurrent Denoising Autoencoder

(PaperReview) Neural 3D mesh renderer
렌더링 분야에 신경망을 접목하기 위한 시도가 몇년 전부터 이어져 오고 있지만, 3D object가 Projection을 통해 screen space로 넘어간 후엔 2D에서 아무리 loss를 구해도 3D object space까지 gradient를 보낼 수 없다는 근본적인 한계가 있었습니다. 본 논문에서는 Approximated gradient 방법을 제안하여 다른 논문들보다 정확하게 Gradient를 2D space에서 3D object space로 전달할 수 있다고 주장합니다. Continue reading (PaperReview) Neural 3D mesh renderer

(PaperReview) Kernel Predicting Convolutional Networks For Denoising Monte Carlo Renderings
SIGGRAPH 2017에는 딥러닝을 사용한 논문들이 굉장히 많이 발표되었습니다. 그중 ‘Kernel Predicting Convolutional Networks for Denoising Monte Carlo Renderings’는 CNN을 사용하여 General하고 Complex한 상황에 대응하는 Denoising Filtering Kernel을 찾아내는 과정에 대해 이야기합니다. Continue reading (PaperReview) Kernel Predicting Convolutional Networks For Denoising Monte Carlo Renderings

(PaperReview) Image-to-Image Translation with Conditional Adversarial Networks(Pix2Pix)
Image to Image translation 기법 중 하나인 Pix2Pix 의 논문과 다양한 부가 자료들을 읽고 정리한 PPT 파일입니다. Continue reading (PaperReview) Image-to-Image Translation with Conditional Adversarial Networks(Pix2Pix)

(PaperReview) Geometrically-correct projection-based texture mapping onto a Deformable object
본 논문은 구부러지고 꼬거나 접을 수 있는 substrate에 대한 프로젝션 매핑 시스템을 제안합니다. 프로젝터와 카메라를 결합한(=Procam) 광학 기반의 마커 추적 방식으로, Registration을 유지하는 것 뿐만 아니라 표면 위에 추가적인 디지털 페인팅 또한 가능합니다. Continue reading (PaperReview) Geometrically-correct projection-based texture mapping onto a Deformable object

(PaperReview) Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
2019년 5월 삼성 모스크바 AI Research에서 arXiv에 퍼블리시한 퓨샷러닝 논문입니다. 단 한장의 이미지로 움직이는 talking head를 만들어주는 네트워크로, 메타 러닝을 퓨샷 러닝에 적용해 빠른 학습 시간을 자랑합니다. Continue reading (PaperReview) Few-Shot Adversarial Learning of Realistic Neural Talking Head Models

(BookSummary) Classification and Ensemble (「파이썬 머신러닝 완벽 가이드」)
「파이썬 머신러닝 완벽 가이드」 라는 책의 chapter 4-1 ~ 4-3 내용에 제 입맛대로 살을 좀 붙인 슬라이드입니다. Continue reading (BookSummary) Classification and Ensemble (「파이썬 머신러닝 완벽 가이드」)

(PaperReview) CNN for Sentence Classification
이강희 교수님 인공지능특론 대학원수업 발표에 사용한 PPT입니다. 문장 수준의 분류 문제에 word vector와 합성곱 신경망(CNN)을 도입한 연구와 한국어에 최적화된 단어 임베딩 학습 방법을 분석하고, 최적의 성능을 낼 수 있는 말뭉치 및 하이퍼 파라미터가 모델 성능에 미치는 영향을 분석한 연구를 공유합니다. Continue reading (PaperReview) CNN for Sentence Classification
(PaperReview+Test) A Versatile Learning based 3D Temporal Tracker - Scalable, Robust, Online
642개의 정점을 가진 Geodesic Grid의 각 vertex로부터 깊이 이미지 및 Object Transformation 정보를 얻고, Random Forest Regressor로 학습해 다음 프레임의 Object Transformation을 예측하는 연구입니다. 해당 논문을 리뷰하고 구현하며 얻은 경험을 공유합니다. Continue reading (PaperReview+Test) A Versatile Learning based 3D Temporal Tracker - Scalable, Robust, Online

(PaperReview+Test) 3D shape reconstruction from sketches via multi view convolutional networks
“3D shape reconstruction from sketches via multi view convolutional networks”는 U-Net과 VanilaGAN을 활용해 스케치(Front, Side)로부터 3D Mesh를 복원해 내는 연구입니다. 페이퍼 리뷰 자료와 함께 해당 연구를 재현한 경험을 공유합니다. Continue reading (PaperReview+Test) 3D shape reconstruction from sketches via multi view convolutional networks

(번역중) 시맨틱 세그멘테이션을 위한 딥러닝 알고리즘 리뷰
본 글은 Medium 유저 ‘Arthur Ouaknine’의 Review of Deep Learning Algorithms for Image Semantic Segmentation를 번역한 글입니다. Continue reading (번역중) 시맨틱 세그멘테이션을 위한 딥러닝 알고리즘 리뷰
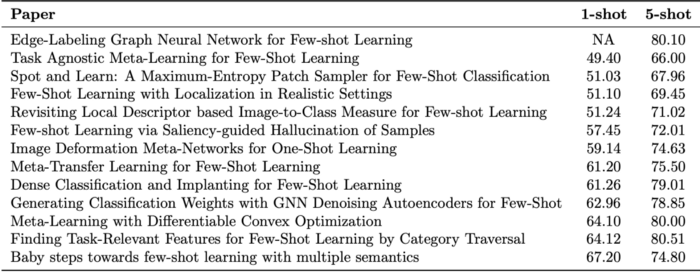
(번역중) CVPR 2019의 Few-Shot Learning
본 글은 Medium Towards Data Science ‘Eli Schwartz’의 Few-Shot Learning in CVPR 2019를 번역한 글입니다. Continue reading (번역중) CVPR 2019의 Few-Shot Learning
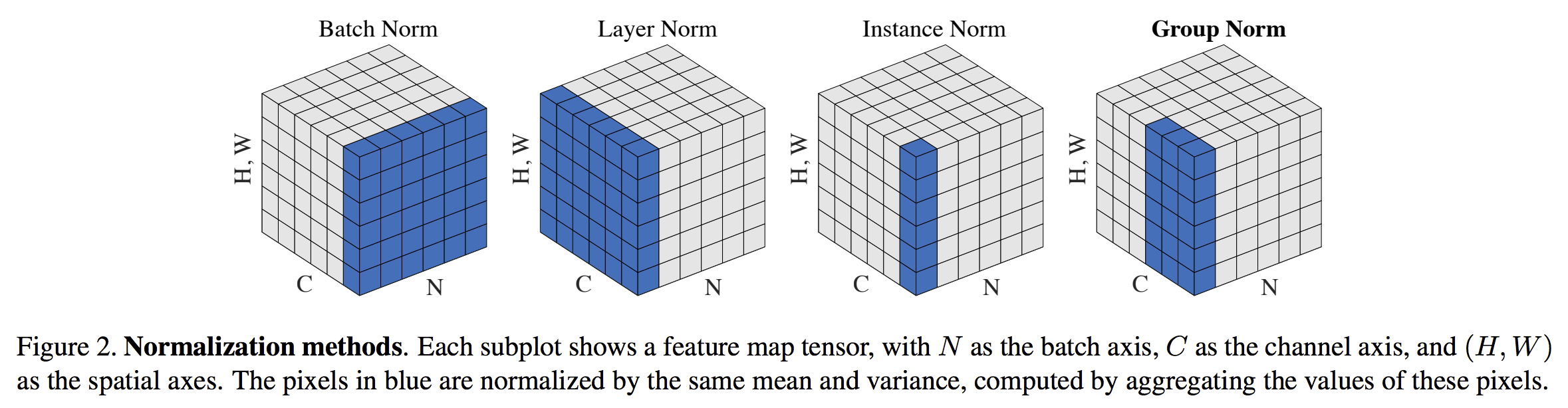
(Normalization) BN이후의 다양한 정규화 기법들
Batch Normalization 이후의 다양한 정규화 기법들에 대해 알아봅니다. Continue reading (Normalization) BN이후의 다양한 정규화 기법들

Python OpenCV Filters Test
애니메이션 캐릭터 얼굴의 엣지를 찾기 위해 다양한 엣지 검출 알고리즘으로 테스트를 수행해본 결과를 공유합니다. Continue reading Python OpenCV Filters Test
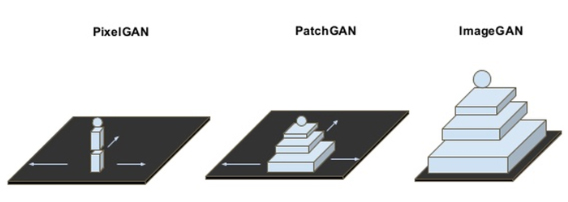
(NN Methodology) PatchGAN Discriminator 뽀개기
Image to image tralslation 분야를 공부하다보면 피해갈 수 없는 개념이 하나 등장합니다. 바로 PatchGAN Discriminator 구조인데요, Generator 부분이야 그렇다쳐도 patch 단위로 Discriminate를 한다는 컨셉이 그다지 직관적으로 와닿지는 않습니다. 이번 포스팅에서는 Pix2Pix와 같은 Image to image translation에서 빼놓으면 섭섭한 PatchGAN Discriminator 구조에 대해 알아보겠습니다. Continue reading (NN Methodology) PatchGAN Discriminator 뽀개기