(PaperReview+Test) 3D shape reconstruction from sketches via multi view convolutional networks

“3D shape reconstruction from sketches via multi view convolutional networks”는 U-Net과 VanilaGAN을 활용해 스케치(Front, Side)로부터 3D Mesh를 복원해 내는 연구입니다. 페이퍼 리뷰 자료와 함께 해당 연구를 재현한 경험을 공유합니다.
- review date: 2019/03/20 (by Meyong-Gyu.LEE @Soongsil Univ.)
- Korean review of '3D Shape Reconstruction from Sketches via Multi-view Convolutional Networks'(CVPR 2017)
3D shape reconstruction from sketches via multi view convolutional networks는 U-Net과 VanilaGAN을 활용해 스케치(Front, Side)로부터 3D Mesh를 reconstruction하는 연구입니다. 기존 연구들이 Voxel과 3D CNN 기반으로 진행되어 온 반면 본 논문은 스케치를 이용해 12개 뷰포인트에 대한 Depth map을 예측하고 그로부터 Normal map과 Mask를 추출하여 3D point cloud를 생성합니다. 이후 이 Point cloud로 screened Poisson Surface Reconstruction algorithm을 돌려 3D mesh로 변환 및 fine-tuning 과정을 거칩니다. 스케치로부터 Reconstruction 과정에 사용되는 Depth map이나 Normal map, Mask map과 같은 Information textures를 예측한다는 점에서 Sketch → Information textures로의 Image to image translation 문제로 보아도 되겠습니다.


본 논문은 12GB 이상의 메모리 용량을 요구합니다. 인풋 이미지 두 장을 통해 12장의 Information Texture(mask, depth, normal map)들을 학습하고 추론하다보니 배치 사이즈를 1로 잡아도 OOM에러가 뜨기 일쑤였습니다.
제가 연구에 사용한 장비가 RTX 2080TI였는데, CUDA OOM에러가 발생해 공유 GPU메모리까지 끌어다 학습했습니다. 베이스라인이 자꾸 CUDA OOM때문에 학습이 불가능해서 Per_process_gpu_memory_fraction 대신 allow_frowth = True 로 두고 학습을 진행했습니다. TF의 동적 배치자(Dynamic placer)가 이전에 실행한 그래프의 계산 시간, 각 연산에 사용되는 입출력 텐서 전체 크기 추정치, 장치의 가용 VRAM용량 등을 캐시 형태로 저장하고 있어 해당 이슈가 발생했던 것 같습니다. 이 부분은 혹시 잘 아시는 분이 계시면 댓글로 정정 부탁드리겠습니다.
저자들이 제안하는 모델은 스케치 이미지의 지역적인 특징을 잘 살려내지 못하며, 이는 즉 스케치의 일부 부분이 활용되지 못함을 의미합니다. (특히 고양이 수염과 같은 부분이 이에 해당합니다.) 또한 Front와 Side sketch 이미지가 다른 뷰포인트에서 추론된 결과물에 의해 무시되는 경향이 있습니다. 어찌보면 명확한 슈퍼비전으로 볼 수 있는 Front와 Side sketch가 무시되는 것이죠. 뿐만 아니라 모델이 예측한 마스크 맵의 퀄리티가 낮으며, 이는 GAN Loss로 단순한 Cross Entropy가 사용되었기 때문이라고 추측하고 있습니다. 해당 논문을 개선해 보고자 Discriminator에 PatchGAN 구조를 적용하여 Loss를 Patch 단위로 모을 수 있도록 함과 동시에 Pix2Pix의 Loss function을 적용해 보았습니다만 드라마틱한 개선은 확인할 수 없었습니다.
PatchGAN을 사용하기로 한 건 Pix2Pix 논문에서도 언급하고 있듯 MRF(Markov Random Field)관점에서 G의 결과물을 해석하기 위함입니다. 모델이 추론한 Pix2Pix 논문에 자세히 언급이 되어 있지 않아 스스로 찾아본 바 MRF는 다음과 같은 특징이 있습니다.
- 이미지의 statistical dependencies가 local level에 존재한다고 가정
- Local Image의 Likelihood를 학습하는 방식으로, Patch 직경보다 먼 pixel들은 서로 Independent하다고 가정
- 무조건 Bayesian Approach로 모델링
- MRF는 Markov assumption을 가진 Random Field를 의미
- 1차 마르코프 가정 : 시간 $𝑛$에서 어떤 사건이 관측될 확률은 시간 $𝑛−1$에서의 관측 결과인 $q_{n-1}$에만 의존한다. (이때 Random Variables는 이미지의 각 픽셀이고, Random Field는 각 픽셀들의 집합으로 생각 가능.)
Predicted Normal, depth map의 퀄리티가 낮은 가장 강력한 이유로 PatchGAN이 적용되지 않았던 것을 의심해 보았으나 효과적인 해결책이 되어 주지는 못했습니다.

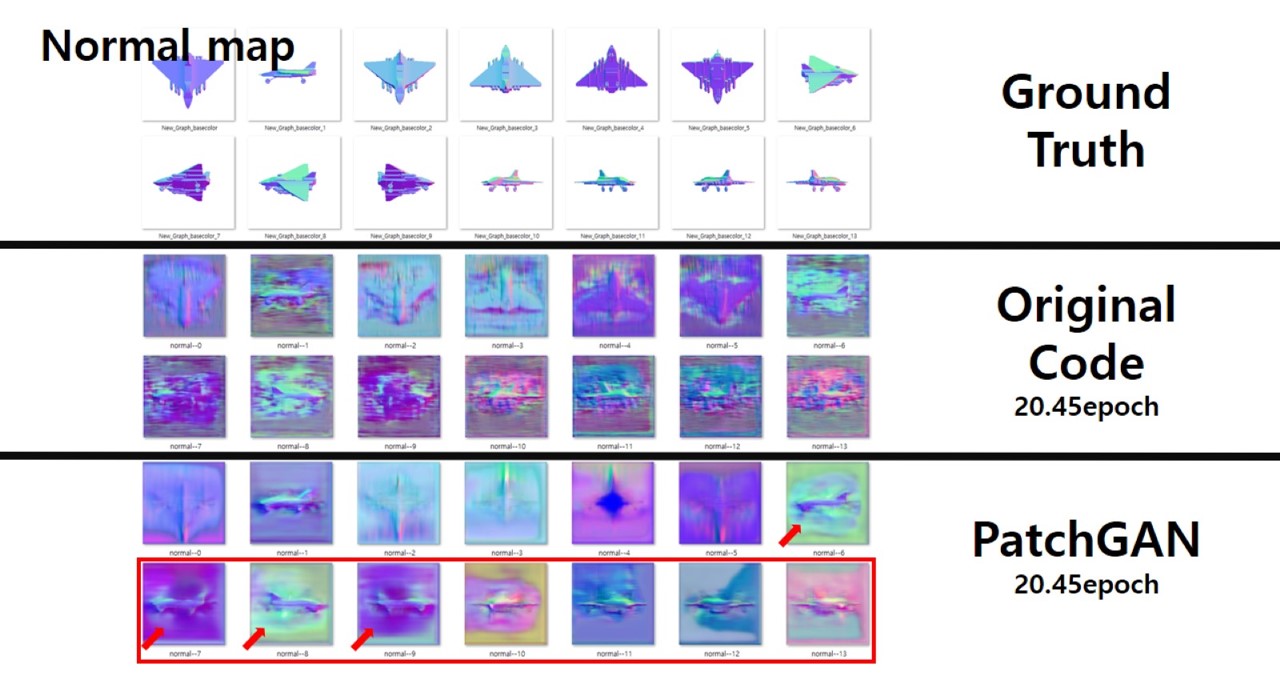

또한 보잉 여객기와 같이 자주 등장하는 모델에 대해서는 꽤 잘 추론하지만 스타워즈 시리즈에 나올 법한 괴상한 우주선은 아예 추론하지 못하는 모습을 보이기도 했습니다.

저는 이미지의 지역 정보를 보지 못하는 이유가 학습데이터의 정보량을 네트워크가 충분히 담지 못하고 있기 때문으로 생각했고, 그래서 백본을 U-Net에서 ResNet으로 변경해 보았습니다.
맨 마지막으로 시도해 봤던 구조가 CycleGAN의 ResNet Generator + RF 70 + LSGAN Loss + Batch Instance Normalization 조합이었는데, 베이스라인 대비 메모리 사용량이 1.5배가량 줄어들긴 했습니다. TF 버전과 CUDA 버전을 각각 1.14와 10.0버전으로 올려 100epoch을 학습시킬때 기존에 7일정도 걸리던 시간 또한 4.3일로 줄어들었습니다.
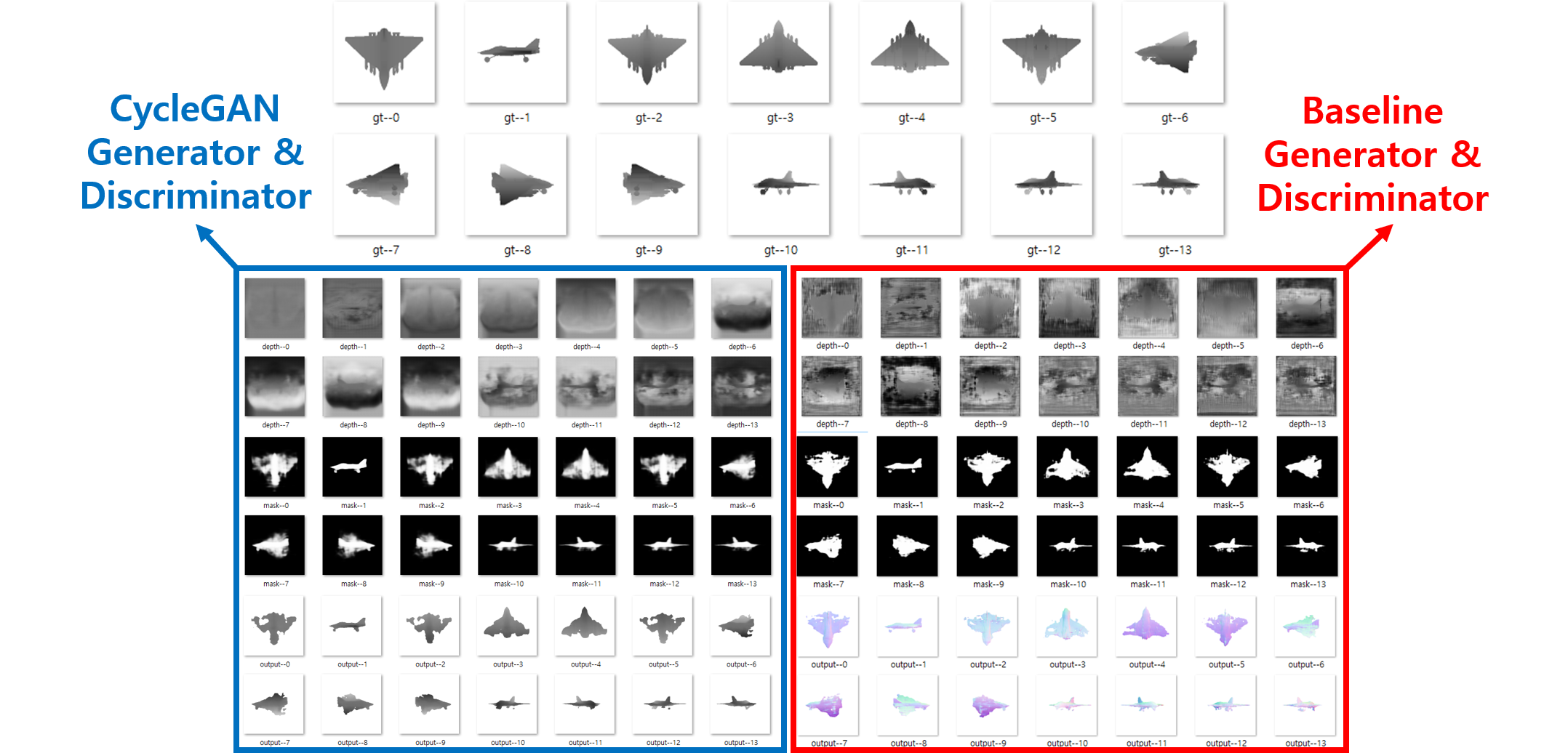
이후로도 이것저것 시도해 보았지만 유의미한 퀄리티 향상이 일어나지 않아 그 이상의 것은 시도해 보지 않았습니다. 개인적인 감상으론 스케치를 이용해 3D mesh를 만드는 발상이 게임 및 3D 프린팅 분야에서 이상적으로 들릴 수 있겠으나 대다수의 GAN 및 Image to image translation 솔루션들이 그렇듯 아카데믹한 성격이 강하고 상업 목적으로 이용하기엔 한계가 큽니다.
디테일 묘사가 떨어진다는 점은 둘째치고라도 prediction을 얻기 위해 하나의 shape(비행기, 사람 등)에서 Titan X GPU 기준 2일(4K training sketches, batch size 2), RTX 2080TI 기준 약 일주일(batch size 1)이 학습 과정에 소요된다는 점(그나마 다행인 것은 학습 완료 후 prediction에는 대략 4.5초 정도밖에 걸리지 않습니다.), predicted information texture들로 3D mesh를 구성하는데 대략 4초가 소요되지만 Intel Xeon E5-2699 v3(약 350만원) CPU를 두 대나 사용한다는 점에서 상당히 비효율적이라고 할 수 있겠습니다. (I7-9700k는 40분 소요)